A real tree generally has a single trunk which splits into limbs, branches, twigs, and finally leaves. In a geneological tree, every person starts with a set of parental DNA, and might produce one or more offspring. In either tree, the whole is built by a simple repetition of this one-to-(potentially)-many relationship.
Once a tree is complete, you can follow a lineage up or down by seeking ancestors or children. And you can go horizontally through a family group by seeking siblings.
The DOM structures an HTML document like a geneological tree: each document element has a single parent and the possibility of descendents. Here's the structure for the first part of this page:
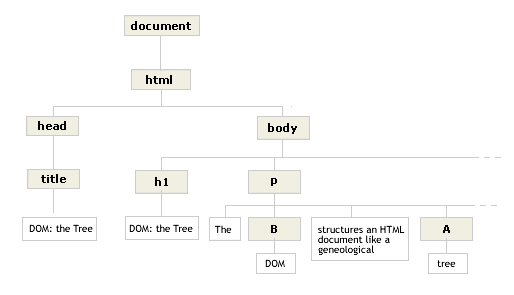
DOCUMENT is the ancestor of all elements in the tree. Its child, HTML, has 2 children, HEAD and BODY. These siblings are the children of HTML because they occur between the opening and closing HTML tags. This principle organizes the entire tree — anything an element contains is treated as its descendent.
To flesh out the implications of this, compare the diagram of P above with the markup for this page's 1st paragraph:
<p>The <b>DOM</b> structures an HTML document like a geneological <a href="#">tree</a>: each document element has … </p>
"Node" is a generic term for a block of memory that stores some data, and that refers to one or more other nodes.
In the DOM, a "text node" is an endpoint, like the leaf at the end of the twig. It never refers to children. An "element node," on the other hand, often has multiple descendents, as well as properties and methods.
P's 1st child is a text node containing "The ". Its 2nd child is not the word "DOM," but the element node, B. As DOM: About Objects describes, a browser creates an object for every element in a document. So B is a full-blown object, too. This makes B's child, "DOM", a grandchild of P (even though it's displayed in-line with P's text).
The rest of the paragraph works the same way. P's 3rd child is more text, its 4th the element A, and its 5th the remaining text. The 2 sentences you see at the top of this page are built from P's 5 children (and their descendents).
When the browser builds the document tree from your HTML markup, it busily catalogs the relations between all the objects it creates from your HTML tags. In fact, it embeds these relationships into the objects themselves, as part of their properties.
Here are the relationship properties the first P element contains:
parent (refers to BODY) previousSibling (refers to H1) nextSibling (refers to paragraph 2, which contains the diagram above) firstChild (the text node "The") lastChild (the last text node, which starts with "each...") childNodes[0..n] (childNodes[0] = firstChild, childNodes[1] refers to B, etc. (If P had only 1 child, "firstChild," "lastChild," and "childNodes[0]" would be synonyms.)
Well. Good for the browser, you might think. And you'd be right, if the browser kept all this information to itself. But it doesn't. It treats a document as a set of related objects and interfaces — it gives you access to all these properties.
To use them, you must find them.