Way back in May 2001, Tim Berners-Lee published "The Semantic Web: A new form of Web content that is meaningful to computers will unleash a revolution of new possibilities" in The Scientific American. Describing the vision of the semantic web in this popular magazine, he suggested a web where deposits of semantic information could be exploited. Consider this scenario:
At the doctor's office, Lucy instructed her Semantic Web agent through her handheld Web browser. The agent promptly retrieved information about Mom's prescribed treatment from the doctor's agent, looked up several lists of providers, and checked for the ones in-plan for Mom's insurance within a 20-mile radius of her home and with a rating of excellent or very good on trusted rating services. It then began trying to find a match between available appointment times (supplied by the agents of individual providers through their Web sites) and Pete's and Lucy's busy schedules.
I'll be a curmudgeon and point out that this hasn't happened yet for a host of reasons, both technical and cultural that are interesting, but not part of this course.
T B-L e-mail November 8, 2010
Do I assume that the dog food data does not work in tabulator because it the data does conneg and assumes that if you can handle HTML then you should not be given RDF?
With tabulator, http://data.semanticweb.org/conference/iswc/2010/ redirects to http://data.semanticweb.org/conference/iswc/2010/html
which is an HTML web page, not RDF.
If you are publishing data, please publish it primarily as data, not as HTML, for clients which can take both equally well. Or don't use conneg.
Interesting -- if I start at http://data.semanticweb.org/workshop/cold/2010/rdf then I can browse, because tabulator in outline mode uses a stronger preference for RDF.
Tim
In the past decade, we have witnessed two interlocking phenomena: (1) The creation of an information architecture, RDF (Resource Description Format), and (2) An "open" data movement (see this statement by a scientist). When these two phenomena snapped together, the result was the creation of many depositories of millions of RDF records in open web space. The general name for all this is LOD - the Linked Open Data web (or the Linking Open Data web), which Berners-Lee has evaluated as "The Semantic Web done right".
Web of Linked Data
The home of LOD describes the goal "is to extend the Web with a data commons by publishing various open data sets as RDF on the Web and by setting RDF links between data items from different data sources."
Here is the LOD data cloud as of July 2009, which features over 4.7 billion RDF triples, which are interlinked by approximately 142 million RDF links (May 2009). Drag this image to see all of it. Note the "centrality" of DBpedia.
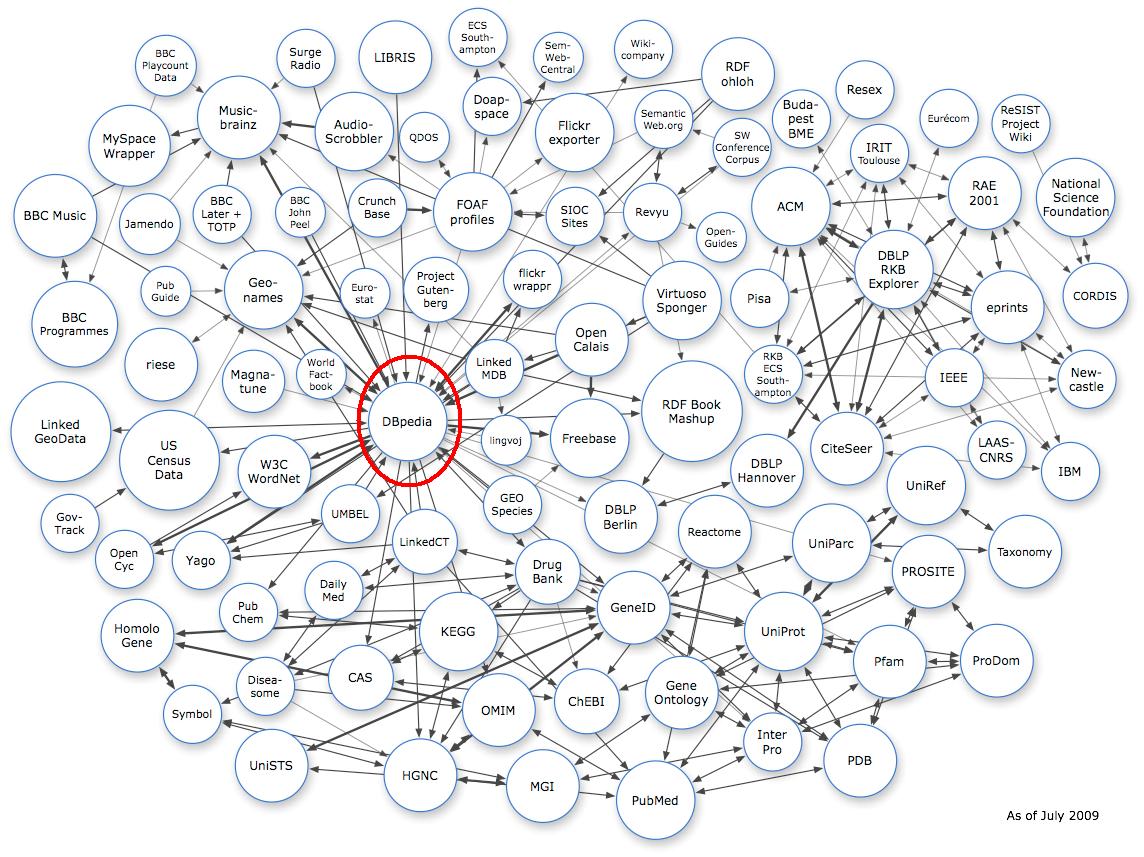
RDF data sets that are part of the emerging Web of Linked Data include DBpedia, a compilation of the "structured" information from Wikipedia. (Many, but not all Wikipedia pages, feature a info box on the righthand side that provides structured information about the topic of the article).
The page "Accessing the DBpedia Data Set over the Web" describes a public SPARQL endpoint.the best SPARQL tutorial that I've seen is "SPARQL by example".
Below is some detailed information about making SPARQL queries to DBpedia, including some strategy about MIME types and various problems encountered with inconsistent information architecture in DBpedia. This content is taken from Wikipedia on a web page and Gathering flowers from DBpedia.
While there are many things to learn from a close examination of the following material, certainly one important lesson is that things are still rough and ready out there in Semantic Web land with lots of gotchas and weirdnesses. Simple it ain't.
Wikipedia on a web page
Presented below is a Greasemonkey script that make calls to DBpedia using the mime types of text/html. The script presents the contents within a JavaScript alert function.
The SPARQL request
SPARQL is an RDF query language. These scripts make XMLHttpRequests to the public SPARQL endpoint provided by DBpedia ("http://dbpedia.org/sparql"). The same SPARQL query is used with both scripts: it asks for the abstract of civil engineering in the English language:
// REBUILD THIS STRING AS ONE LINE
SELECT ?abstract WHERE
{
{ <http://dbpedia.org/resource/Civil_engineering>
<http://dbpedia.org/ontology/abstract>
?abstract
FILTER langMatches( lang(?abstract), 'en') }
}
Greasemonkey script
Using mime type text/html and XPath
Declaring a mime type of 'text/html' gives a payload structured as an HTML table element with two identical table data <td> elements. The payload is structured like this:
<table class="sparql" border="1">
<tr>
<th>abstract</th>
</tr>
<tr>
<td>Civil engineering is ... in 1905.</td>
</tr>
<tr>
<td>Civil engineering is ... in 1905.</td>
</tr>
</table>
With XPath you can easily target the first <td> element: ".//td[1]". To facilitate the use of XPath, a new HTML element is created and the payload becomes its innerHTML content. The document evaluate function produces a nodelist. SnapshotItem(0) is the single node in this nodelist and its firstchild.nodeValue is the textual content of the <td> element.
var mashPage = document.createElement("div");
mashPage.innerHTML = response.responseText;
var myNodeList;
myNodeList = document.evaluate(".//td[1]",mashPage,null,XPathResult.UNORDERED_NODE_SNAPSHOT_TYPE,null);
alert(myNodeList.snapshotItem(0).firstChild.nodeValue);
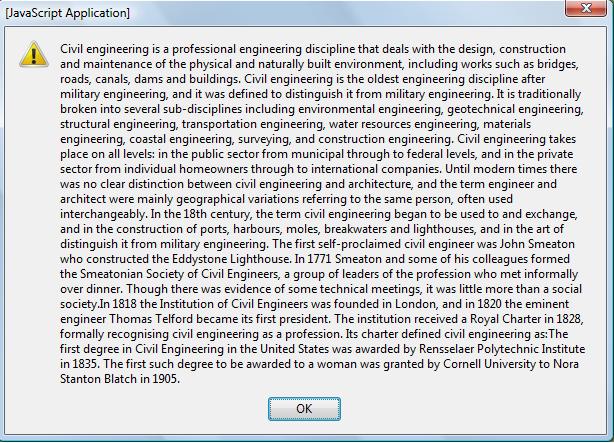
The script: "civilEngineering.user.js"
State flowers from DBpedia

American states commonly name one or more flowers as their state flower; for example, the California Poppy is the state flower of California. Harvesting state names and flowers from DBpedia illustrates several important strategies for the web-page developer who has the ambition to make an AJAX call to DBpedia, unpack the payload and patch it into a web page.
Structured information
DBpedia provides Web access to the structured information that appears in the sidebar "infobox" feature of many Wikipedia articles. An infobox style guide comments: "In theory, the fields in an infobox should be consistent across every article using it; in practice, however, this is rarely the case, for a number of reasons." While this comment focuses on the unpredictable presence or absence of fields in infoboxes, the developer must also be concerned about variations in the structure of the content of the fields. This variation is illustrated by the XML payload listing state flowers discussed below.
A SPARQL query for state flowers
The blog "Meow meow meow" uses the following SPARQL query to list American states and their flowers.
SELECT ?state ?flower WHERE {
?state skos:subject <http://dbpedia.org/resource/Category:States_of_the_United_States> .
?state dbpedia2:flower ?flower
}
Here is the raw XML payload received when the MIME type is set to "application/sparql-results+xml":
An examination of this XML output reveals (1) some complete state/flower repetition (i.e., California and California Poppies appear six times), (2) some partial state/flower repetition (i.e., Alabama has two state flowers), (3) some embedded Hex HTML escape codes (see Florida's entry), (4) some embedded HTML code (see West Virginia's entry), and (5) some <literal> elements mixed in with <uri> elements.
No claim is made here that this is an exhaustive list of irregularities, since there seems to be little control of the source of DBpedia's content which is community input.
If the developer wishes to glean from this payload the pattern of state name/state flower, then both the state name and flower name data must be reduced, the repetition in the data must be controlled, and non-text characters transformed. The loop through the payload that accomplishes this can't assume the uniform presence of the <uri> element.
Strategizing which MIME type to use
The "application/sparql-results+xml" MIME type produces data structured like this:
<result>
<binding name="state">
<uri>http://dbpedia.org/resource/Alaska</uri>
</binding>
<binding name="flower">
<uri>http://dbpedia.org/resource/Forget-me-not</uri>
</binding>
</result>
The "application/sparql-results+json" MIME type produces data structured like this:
{
"state": { "type": "uri", "value": "http://dbpedia.org/resource/Alaska" } ,
"flower": { "type": "uri", "value": "http://dbpedia.org/resource/Forget-me-not" }
}
Unpacking either of these structures requires some strenuous node traversal. For example, unpacking the XML requires cycling through all the "results" nodes, finding the child node with the attribute "name", checking that this "name" attribute has the value "state", and then reaching inside for its "childNodes[1].firstChild.nodeValue". Applying this method to the flower nodes is slightly more complex as they may occur as <uri> elements or <literal> elements. Unpacking the JSON results is not appreciably simpler.
The "text/html" MIME type produces a much simpler structure that immediately finesses the <uri>/<literal> problem:
<tr>
<td>http://dbpedia.org/resource/Alaska</td>
<td>http://dbpedia.org/resource/Forget-me-not</td>
</tr>
The remainder of this example uses the "text/html" MIME type, and presumes that a Greasemonkey script will be running in a Firefox browser.
SPARQL endpoint and query
The targeted SPARQL endpoint is "http://dbpedia.org/sparql".
The "Meow meow meow" SPARQL query above is appropriate for the SPARQL Explorer but needs to be elaborated with an explicit namespace for "dbpedia2" to work in a Greasemonkey GM_xmlhttpRequest:
PREFIX dbpedia2: <http://dbpedia.org/property/>
SELECT ?state ?flower
WHERE
{
?state skos:subject <http://dbpedia.org/resource/Category:States_of_the_United_States> .
?state dbpedia2:flower ?flower
}
Collecting <tr> values
The aim is to create a nodelist of <tr> nodes. Placing the responseDetails.responseText inside a new document element permits the use of an XPath query to create a nodelist of <tr> nodes.
var newTable = document.createElement("table");
newTable.innerHTML = responseDetails.responseText;
var tr = document.evaluate('//tr', newTable, null, XPathResult.UNORDERED_NODE_SNAPSHOT_TYPE, null);
Getting state and flower information
Looping through the nodelist of <tr> nodes will reveal the state and flower information with a minimum of node traversal. There are two interesting things to note about this loop. It begins at "1" to account for the very first <tr> element in the raw data which contain table headings. The "1" and "3" childnodes represent the state and flower information.
for (var i = 1; i < tr.snapshotLength; i++)
{
tr.snapshotItem(i).childNodes[1].firstChild.nodeValue); // state
tr.snapshotItem(i).childNodes[3].firstChild.nodeValue); // flower
...
}
Some JavaScript post-processing
The JavaScript lastIndexOf() and substring() can be used to isolate state and flower names.
An associative array indexed on state name holds flower data. At this moment, there is a hack to accommodate a state with two flower names.
DBpedia's American State and Flower information (June 2009)
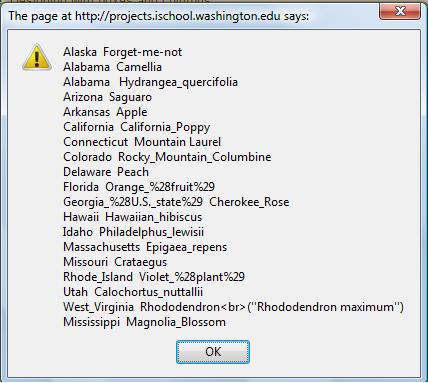
Greasemonkey script: "DBpediaStateFlower.user.js"