Terry Gray
University of Washington
Rev 99.08.13.22
Enterprise Quality of Service (QoS) concerns the transformation of current best-effort, single-class-of-service internets into systems that can offer one or more levels of preferred service to certain classes of users or applications. The goal of having a network with preferred service levels is to increase the probability that critical or demanding applications will receive enough bandwidth (and absence of delay) to succeed. The importance of having preferred service levels depends on the amount of (instantaneous) congestion in the enterprise network. The term QoS is susceptible to many different definitions, and a wide spectrum of implementation approaches. Choosing the "best" one will require making decisions about the relative costs of network capacity and the machinery to manage it.
There are three kinds of people with respect to network QoS: optimists, pessimists, and fence-sitters. Optimists believe that the cost of bandwidth is or soon will be less than the cost of complex mechanisms for managing it. Pessimists believe that bandwidth will always be scarce and therefore complex end-to-end QoS mechanisms will be essential in order for advanced applications to succeed in a shared Internet infrastructure. The fence-sitters want to believe the optimists (and indeed do believe them with respect to campus/enterprise bandwidth) but aren't so sure about wide-area bandwidth (notwithstanding advances such as DWDM). In any case, the fence-sitters figure they better have a contingency plan in case the pessimists are, at least partially, right.
This paper attempts to identify key issues in enterprise QoS, and then outlines a "fence-sitter" strategy that emphasizes operational simplicity but also tries to hedge bets. Key points include:
Said differently, our strategy is to build a network infrastructure that can support multiple classes of service without introducing the complexity of per-session admission control (via per-user authentication or per-packet or per-flow lookups or reservations). It should be amenable to several different premium service policy models, e.g. charging per-port subscription and/or usage fees and/or support for differential queuing based on application need, especially delay-sensitivity. The UW model also allows for end-systems to signal campus border routers acting as bandwidth brokers (e.g. via RSVP) if necessary to negotiate for wide-area premium service, and for "very long term" reservations (i.e. segregated bandwidth) or MPLS virtual circuits among enterprise sites for IP telephony, IP videoconferencing, etc.
01. INTRODUCTION
01.1 Goal
01.2 Context
01.3 Definitions
02. FUNDAMENTALS
02.1 Congestion
02.2 Tools in the QoS Toolbox
02.3 Managing scarcity
02.4 Prioritization Criteria
02.5 The Odds of Congestion
02.6 Details
02.7 Axioms
02.8 Conundrums
02.9 An Imperfect World
02.10 Differences between LANs and WANs
03. ENVIRONMENT
03.1 Context
03.2 Application Drivers
03.3 Usage Scenarios
03.4 Subnet Congestion: How Much QoS Is Needed?
03.5 Border Crossings
03.6 Integrated Services, Take Two.
03.7 Capacity Planning and Cost Recovery
03.8 Reality Check
04. REQUIREMENTS
04.1 Success Criteria
04.2 Goals for Congested Links
04.3 Scheduling and Reservations
04.4 Segregation or Reservation?
04.5 Is User Authentication a Must?
04.6 Using Multiple Queues
04.7 Reliability is Job One
05. ADMINISTRATION
05.1 Campus Economies and the QoS Policy Space
05.2 Practical Prioritization Policies
05.3 Pricing
05.4 Gaming the System
05.5 Support Costs
05.6 Inbound vs. outbound traffic.
05.7 Moderating demand for wide-area bandwidth.
06. SUMMARY/CHOICES
06.1 The QoS Toolkit
06.2 Key Assumptions
06.3 Key Questions
06.4 Key Choice Matrix
07. STRAWMAN
07.1 Applicability
07.2 Selected Requirements
07.3 General Approach
07.4 Premium-port Subscriptions
07.5 Functional Responsibilities
07.6 Alternatives Considered
08. CONCLUSIONS
09. ACKNOWLEDGMENTS
The purpose of this section is to explain the goals of this document, the context in which it was written, and the definitions and conventions used in the rest of the document.
The goal of this document is to explore the problem of developing and deploying Quality of Service (QoS) mechanisms for enterprise networks that are reliable, manageable and cost-effective. More specifically, it will attempt to make the case that a "minimalist" approach to QoS is both adequate and advantageous within enterprise nets. In other words, we will argue that the best way to balance the tradeoffs among efficient bandwidth utilization, application performance requirements, and the cost of enterprise/campus QoS mechanisms is to focus on maximizing network capacity and minimizing the complexity of the QoS solution itself.
This document is written from the perspective of a network administrator concerned about providing the best possible network services while at the same time trying to come to terms with the complexities of QoS and its impact on campus/enterprise network design and operation. It is essentially a case study of the University of Washington's efforts to design and define requirements for a major campus network upgrade project.
A crucial assumption of this discussion is that the "on-campus" QoS problem is quite different from the "off-campus" QoS problem because of the extraordinary difference in the cost of local vs. wide-area bandwidth. Even though both share many characteristics and management requirements, the economics of adding capacity on-campus make QoS there amenable to simpler solutions than off-campus QoS. The same fundamental principles apply to both problems, however, and although the emphasis here is on campus QoS, the wide-area problem must be considered as well, to make sure that the campus solution does not undermine the wide-area QoS approach, and to make sure a compatible management and policy framework exists. (This is the point where a real optimist would postulate that wide-area bandwidth will be just as inexpensive as on-campus bandwidth in the not-distant future, but we prefer not to count those chickens until they've hatched.)
The term "QoS" is susceptible to a wide spectrum of definitions, ranging from the simplest priority-queuing strategy to full-out reservation-based, per-flow, user-authenticated, admission control and end-to-end bandwidth/delay guarantees. That continuum reflects increasing probability that an application, if allowed to proceed at all, will have the network resources it needs for the duration of the session. It also reflects increasing development, deployment, and on-going implementation costs and complexity.
We will use the term "hard QoS" for mechanisms that seek to provide specific network performance guarantees to applications (actually, bandwidth/delay reservations for an imminent or future data flow). Such Quality of Service is usually characterized in terms of ability to guarantee to an application specified peak and average bandwidth, delay, jitter, packet loss, and packet error rates.
The term "Class of Service" represents the less ambitious approach of giving preferential treatment to certain kinds of packets, but without making any performance guarantees. One particular Class of Service approach is called "DiffServ" for "Differentiated Services". The DiffServ goal is to provide not only the traditional "best effort" service, but something better than "best effort" as well. It attempts to avoid the cost of maintaining per-flow state in core routers by treating similar types of traffic in the same way, that is, by aggregating individual flows into equivalence classes. If the diff-serv approach can meet application requirements, at least within the enterprise, then it follows that the added cost and complexity of "hard" QoS mechanisms can be avoided. The IETF DiffServ working group has defined several "Per Hop Behaviors" to support the differentiated services model. Various groups are working on adding the concept of "Bandwidth Brokers" --essentially admission controllers-- to enhance the DiffServ model in hopes of being able to give some performance assurances to applications using DiffServ.
In this paper, "QoS" will be used in the most general sense, not just in reference to "hard" QoS mechanisms, and "eQoS" will sometimes be used as shorthand for "enterprise QoS". Further, "enterprise" and "campus" will be used interchangeably, even though large enterprises will undoubtedly have multiple locations connected by relatively low-bandwidth links --presenting essentially the wide-area QoS problem to those remote sites.
The term "preferred service" will be used in the generic "better than best-effort" sense, rather than as the name for any specific or precise queuing discipline.
Some of the terms that will be used in the context of resource management include:
TOS refers to the "Type Of Service" header field in an IP packet, which is now used in support of the "DiffServ" specification. The term "integrated services" refers to efforts to combine voice, video, and data traffic over the same network infrastructure. And "CBQ" means "Class-Based Queuing", the methodology behind "Class of Service" provisioning.
Finally, "Layer-2 authentication" refers to a mechanism where network access, or "Ethernet dialtone" is available only after the user has been successfully authenticated.
The purpose of this section is to identify some fundamental issues that may impact one's approach to QoS decisions. In particular, we'll discuss the 3 parts of the QoS equation: capacity, demand, and allocation mechanisms.
QoS is all about controlling what happens to packets when there is congestion in a network, i.e. when there is insufficient capacity in the network to deliver all of the offered load without any noticeable queuing delays. This is true both in a datagram-oriented DiffServ context, where individual packets specify a desired "per hop behavior", and also in a "hard" QoS context, where virtual circuits are dynamically created and resources throughout the circuit path are sequestered at call-setup time.
Network congestion results from mismatches between network supply (capacity) and network demand. The mismatch may be a long-term one, or at nano-second time scales. Remember that at any instant in time, a network link is either full or empty... any value in between is a function of averaging interval. The averaging interval is crucial. Network capacity may appear to be ample if one is looking at long-term traffic averages; and while the world is full of leased lines running continually at maximum capacity, the more subtle problem is with short bursts of packets, or peak demand.
Note also that a hard QoS virtual circuit model may protect packets in a particular flow (for the duration of the flow), but it does not mean that packets belonging to other flows will avoid congestion while traversing the very same nodes in the network. If a node is congested, such packets might end up being "tossed on the floor" or, in a hard QoS model, the virtual circuit may not be able to be established; i.e. the user gets a busy signal.
What causes congestion?
When a packet reaches a switch or router port, it may not be possible to forward it immediately to the appropriate output port because the output port (really, the associated link) is busy. This can happen when the output link is slower than the input link and/or when there are multiple flows arriving on different input ports all feeding into one particular output port.
Congestion control.
Whenever a packet cannot be forwarded, it is queued, and if the queue reaches a certain threshold (length), one or more packets must be dropped. Which packets in the queue get dropped depends on the queue management algorithm. Proactive congestion control by a router usually involves a more sophisticated algorithm than just dropping the packets that arrive after queue space is exhausted. Moreover, queue lengths must be bounded in order to keep latency under control.
In some contexts, it's OK for packets to be dropped; indeed it may be necessary, as when TCP searches for the best flow rate for current conditions and uses a dropped packet as an implicit congestion notification. At some point, however, dropped packets translate directly to poor performance, and then the owners/originators/users of those packets come gunning for the network manager. So, in general, dropped packets are not a Good Thing.
In a congestion situation, when premium traffic is given precedence, best-effort traffic must be dropped and/or slow-down (generally as a result of TCP rate adaptation).
Congestion avoidance.
To avoid dropping packets, we need to avoid congestion. Avoiding congestion can be done by:
If a network link is continually saturated, there is little to be done except either increase capacity or reduce demand. However, it is often the case that a particular link would have sufficient capacity for the offered load if the load was more evenly spaced in time; alas, when demand peaks at certain times, the link is not capable of handling the instantaneous demand. In these situations, some form of "demand shaping" may help. Demand shaping involves shifting demand from peak times to off-peak times, but you could say it is the same thing as demand reduction that is focused on peak intervals. Moreover, the timescale for the peaks might be macro or micro: that is, daily or seasonal peaks based on normal human patterns of usage, vs. nanosecond-timescale peaks due to the fractal nature of Ethernet traffic. Specifically:
Congestion zones
Differentiated services have to do with real-time prioritization of packets and queuing disciplines in switches and routers such that, when congestion occurs, preferred traffic will make it thru the network unscathed. Hard QoS goes beyond that to try to make statements about network behavior in the future, and preserving a specified level of performance for the duration of the flow. Either way, without congestion, the QoS problem is a non-problem, so it is useful to think about where congestion is likely to occur in a real network.
Some parts of a network are more likely to experience congestion than others. While "all generalizations are false", it is easier to stay ahead of network congestion (some call it "over-provisioning") in a local subnet using contemporary Fast and Gigabit Ethernet switches than in a wide area network. The enterprise backbone is somewhere in between. The network topology shown in Figure1 illustrates these three "congestion zones". Different QoS strategies are appropriate for different congestion zones, i.e. portions of the network architecture with significantly different probabilities of congestion.
Ways to increase capacity include:
Ways to reduce or shape demand include:
Under the TRAFFIC AUTHORIZATION category, the term "Eligibility control" has to do with who or what can ask for the resource being managed, and under what circumstances. For example, an edge switch might be configured to mark incoming packets from specified (subscribed) ports so that the first router encountered can use that information in making queuing decisions. For example, the router might be configured to ignore the TOS/DiffServ bits in the packet header generated by the end-system unless the packet is from a premium port, or both values might be used in setting the packet priority. (These TOS or DiffServ bits would typically be requesting preferential treatment.) In a class-based-queuing environment, the expectation is that such requests will be acted on by the network as best it can (though there may certainly be policing and ex post facto monitoring/billing.) In a "hard" QoS environment, i.e. one with real-time call-setup reservations, such requests from "eligible" users, stations, or ports are also subject to admission control...
"Admission control" is a the term used in "integrated services" discussions to describe whether or not a request for preferential (or specific) treatment will be honored "by the network". (Although sometimes it is defined to include what we've called eligibility control as well as admission control.) The result of an admission control request might be a "no" (i.e. a busy signal) or it might be part of a negotiation in which a network device responds with the amount of bandwidth that can be made available to the application. In the latter case, we might think of admission control as another form of "quota enforcement by degradation", similar to the result of traffic policing. Except that even with admission control, you'll probably want to do traffic policing to keep the end-system honest.
The TRAFFIC MODIFICATION category includes shaping and/or policing, as described in the following paragraphs.
"Traffic shaping" means modifying the timing of a sequence of packets so as to reduce burstiness. It does not reduce total network demand, but it smooths out the peaks, and in reasonably-provisioned networks, congestion results from the peaks. So traffic shaping can be a very important part of the QoS solution. Unfortunately, traffic shaping is easier said than done, but the capabiity is promised for next-generation routers.
"Traffic policing" is a form of dynamic usage control; think of it as a way of enforcing short-term quotas on a stream of packets. It's a bit like putting a governor on an automobile engine to limit how fast it can go. A common term for a policing mechanism is Committed Access Rate (CAR), or sometimes Committed Information Rate (CIR). These are often defined as the minimum amount of bandwidth made available to the customer, who can --when network conditions permit-- burst traffic at higher rates, usually at extra cost, if we're talking about commercial network services.
CARs are expressed in some number of bits per second and are enforced by some variant of a token-bucket algorithm. The CAR "quota" can typically be applied to either a physical port or by addresses in the packets. What happens to packets that exceed the CAR is another policy question: they might be dropped, or in the wide-area context, they might result in additional charges. In the context of preferred-service access, these "extra" packets might be downgraded to best-effort status, or since that model doesn't provide the user with much incentive to regulate their flow, is harder to implement, and is likely to result in out-of-order packets, the above-quota packets might just be dropped.
Under the TRAFFIC ADAPTATION category, we have these three concepts:
"Protocol adaptation" refers to the rate-adaptive nature of transport protocols such as TCP. Such protocols detect congestion in the network, either explicitly, or --as in the case of TCP-- implicitly (by noticing that packets are getting lost) and slow down their rate of sending accordingly.
"Application adaptation" refers to applications which sense congestion in a network and back off. This is a particularly important property for applications that do not use an adaptive protocol. For example, streaming video applications generally do not use TCP, because it is better to drop a video packet than delay the sequence by retransmitting.
"User adaptation", or "behavior shaping" has to do with changing/shaping behavior of those eligible to make requests for the presumably scarce network resource. Assuming that, in general, people may want more network capacity than is currently available, the goal is to moderate demand to match available capacity by providing feedback to user in the form of psychological, social, or economic cost.
In terms of timescale, these techniques can be ordered thusly:
The short timescale techniques are generally either inherent in the nature of the technology (e.g. TCP rate adaptation) or may be treated so after initial configuration (e.g. traffic policing). The essence of the eQoS debate will revolve around the medium and long timescale techniques. In particular, whether to use post-audit feedback (e.g. top-ten usage lists, usage pricing), or prior-restraint reservations, or neither one!
Here is another cut on these techniques. Suppose we start with the design premise of pure provisioning, no demand control (shaping or reduction), no diff-serv prioritization... just raw bandwidth. How might we motivate the addition of various demand control techniques?
The assumption here would be that even with eligibility controls on who/what can ask for high-priority treatment, one may need to do demand shaping to deal with peaks.
These approaches can generally be grouped according to when the load control decisions occur:
And after the application terminates, there may be post-audit data collection that turns into feedback for behavior shaping (user adaptation); that is, a mechanism to encourage the user to think carefully about his/her need next time they are about to fire up a demanding application!
QoS could perhaps more properly be called simply "bandwidth and queue management" (or perhaps "bandwidth and latency administration"), and it is essentially a problem of allocating a scarce (or potentially scarce) resource. Unlike notoriously finite resources such as laptop batteries, in an enterprise network, the application of money can almost always increase the amount of bandwidth available (at least, the amount of aggregate bandwidth; peak bandwidth will be limited to whatever current technology makes available, e.g. Gigabit Ethernet.) This is good news. Were it otherwise, the only choice would be to devise control or feedback mechanisms to constrain usage ever more aggressively, with no hope of keeping up with demand. Nevertheless, the "tragedy of the commons" applies here. That is, unconstrained demand for a finite and shared resource ends up destroying that resource, or in the case of a network, renders it unusable for everyone.
More on congestion avoidance.
In the previous section on congestion, seven approaches were mentioned for keeping demand in line with currently-available network capacity. These approaches can be applied either to a single-class-of-service network, or to congestion within one of multiple service classes. Three of them require the cooperation of the end-system and/or application:
The other four can be used even without cooperating end-systems and applications (although traffic shaping could also be done in the end-system):
Given some form of behavior shaping, it may be possible to be more relaxed about eligibility control, and perhaps forego it entirely; but even with eligibility and/or admission controls in place, behavior shaping (e.g. cost feedback) may be an important adjunct.
Note that admission control implies a "reservation" or "call setup" mechanism for each flow, whereas the other approaches will work either with or without call setup. While all of the mechanisms have a policy component, traffic shaping may be done as a low-level network congestion avoidance mechanism that is defined by the characteristics of the egress path and is oblivious to the kind of packets being shaped or where they came from. Admission control can be based on arbitrarily complex advance reservation systems and policy databases, or it can simply be a method for dynamic bandwidth reservation for the duration of a flow on a first-come-first-served basis. In contrast, policing, eligibilty and behavior shaping are clearly explicit policy mechanisms that relate to specific users, ports, or end-systems.
Matching supply and demand
Even with the option of adding capacity, there still needs to be a way to keep usage within current limits (both total bandwidth and bandwidth available within each service class). The tools for avoiding congestion listed above are complementary, but not without controversy. The primary debate concerns whether per-flow admission control, especially in the form of advance reservations, is necessary when eligibility controls, quotas (enforced by traffic policing) and/or behavior shaping mechanisms are in place.
Congestion avoidance methods which use price to moderate demand have the side effect of generating revenue that can be useful for expanding network capacity. Clearly campus demand for bandwidth is growing, and accommodating this demand requires investment in additional capacity. Enterprise QoS design decisions are inextricably linked to enterprise funding models.
Key admission control questions
Within any particular "congestion zone", the desireability of using admission control or other "heavy weight" QoS mechanisms depends on the answers to several key questions, in particular: a) Is the cost of bandwidth greater or less than the cost of managing it? b) Is the prevailing economic environment such that a revenue stream exists to allow adding capacity? c) If capacity is insufficient, do you prefer to disappoint users via poor session performance, or via denial of service (busy signals)?
One conclusion: IF bandwidth costs more than managing it, AND there is inadequate revenue for adding capacity, AND busy signals are preferable to degraded sessions, THEN admission control is necessary and desirable (but probably not otherwise).
Granularity
Or "degree of aggregation". QoS may not always be implemented on a per application basis. Rather, there are many cases where network administrators need to apply different prioritization rules to aggregate traffic flows having particular characteristics. Aggregate flow QoS is one tool available to deal with "traffic engineering" problems. An example might be allocating a certain amount of bandwidth on a campus backbone or remote office link for Voice-over-IP traffic. Another example might be the need to establish a limit for all "preferred" traffic so that it does not completely starve all best-effort traffic. But there might still be a specific instance of an application that needed per-user, per-flow resource allocations. Thus, the needs of an individual user and the needs of network administrators may differ with respect to bandwidth allocation granularity.
Nested bandwidth allocations
The differing requirements of administrators and end-users may lead to a need for "nested" bandwidth allocation policies and mechanisms. For example, consider a researcher who requests ten percent of the available bandwidth of a network in order to conduct a particular experiment. Within that ten percent allocation, the experiment may call for differentiating the priority of several classes of traffic. Likewise, in the remaining 90% of the available bandwidth, there may well be other prioritization policies. The result can be complex, because "expedited" traffic that is part of the experiment's 10% allocation would not rightly share the same queue as "expedited" traffic that is part of the "baseline" production traffic profile. Relatively little attention has been given to this problem, even though allocating percentages of channel capacity to different traffic classes, and allowing for different priorities within those classes, is likely to be a very common requirement.
Given a set of policies and mechanisms that result in a particular offered load to the network, the next question is how the network should prioritize those packets entering the system. Said differently, network managers (and network equipment designers) must decide what criteria will be used by switches or routers in deciding which packets will be given preferential treatment. Some possibilities are:
Prioritization decisions are ultimately made on a per-packet basis, but it is possible to associate specific forwarding priorities with a packet stream or "flow" --or even an aggregation of many packet flows. If the flow of packets is associated with specific reserved resources in the switches and routers that are traversed, the flow is similar to a virtual circuit established at the time an application is initiated (or even at session login time) via either static configuration or a dynamic call-setup protocol such as RSVP. Criteria for such virtual circuit priorities generally fall into the same three categories as above. The same is true for QOS reservations, wherein bandwidth is sequestered for a particular session, perhaps on a First-Come-First-Served basis, or perhaps based on privilege, price, or programmatic considerations.
Problems with prioritizing based on application type
One problem with having network devices make queuing decisions based on application type (which loosely corresponds to its "need") is that the information needed to make such decisions might be encrypted. The IPSec standard for end-to-end packet security offers a mode in which TCP and UDP port numbers are opaque, thus precluding network switches from making queuing decisions based on them.
Even if a packet stream is not encrypted, there are other challenges to using an application's type for prioritization decisions: not all applications use globally agreed-upon TCP or UDP port numbers. For example, two people trying to subvert a QOS scheme based on port number could bilaterally choose a particular port for a specific application or experiment-- and worse, some of the most network-demanding applications are port-agile; that is, the data is sent over a port number that is negotiated in real-time via a control channel. Applications implementing the H.323 desktop conferencing protocol are examples of this. Finally, it should be noted that application need is a relative and not an absolute concept. The actual need for any particular application may differ with circumstances. For example, high quality for a desktop video app may be more important in a tele-medicine context than in the case of a college student checking in with parents.
Is physical port eligibility control sufficient?
Suppose a campus network QoS system was designed using only eligibility control based on physical port subscriptions. For argument's sake, suppose that all packets from eligible ports, and only such packets, are treated as high-priority. How well would this scheme work?
Nevertheless, it is easy to imagine that a price-point exists for preferred service that would avoid the problem of everyone subscribing (and the consequence of the network once again having a single service level). Moreover, if subscriptions are combined with an indication from the application that perferred service is needed or desired (e.g. via the TOS/DS bits) then the odds of achieving a successful multi-class network are even better. In fact, it might even turn out that an unrestricted or laissez faire approach to requesting preferred service --without any subscriptions or eligibility control-- might prove to be sufficient, especially if combined with some form of ex post facto feedback to deal with abusive users. We will return later to the question of whether physical port eligibility control is even necessary.
Modern data networks depend on statistical multiplexing. Very few are provisioned to be totally non-blocking. Accordingly, the liklihood of congestion is a function of network topology and access speeds as well as usage patterns. If most users are connected to the network at (switched) 10Mbps, but the backbone is provisioned with 100Mbps and/or Gigabit Ethernet links, it is entirely plausible that congestion within the campus net will be rare --even without implementing any specific congestion avoidance techniques. However, if a substantial fraction of users are connected at (switched) 100Mbps or Gigabit Ethernet, with end-systems and applications capable of driving those rates, it will be much more difficult --though not necessarily impossible-- to avoid peak congestion via pure provisioning.
Could we build a non-blocking campus net? Would we want to?
Consider this: if all 40,000 of UW's network-connected end-systems sent a maximum of 10Mbps into the campus net, the total incoming traffic, gated by the speed of the access ports, would be 300 gigabits/sec or the equivalent of 300 GE router ports and a non-blocking interconnect between them! This is a large number, and the actual need is going to be much smaller, but even the worst-case "non-blocking" design could actually be implemented with products available now or in the near future. Fortunately, statistical multiplexing comes to our rescue here because the probability of all 40,000 of our networked devices sending 10Mbps simultaneously is zero (especially since a growing number of these devices are printers :)
If everyone had a 100Mbps (Fast Ethernet) connection instead of 10Mbps, and actually used it to the max, the non-blocking aggregate bandwidth requirement would obviously increase by an order of magnitude. Here we are saved not only by statistical multiplexing among all the users, but the fact that most desktop systems are not likely to take advantage of a 100Mbps connection, either because of hardware/OS limitations, or because the applications being used don't need it.
We conclude therefore that it would be possible to build a non-blocking campus network, at least at the switched 10Mbps level, but that would be serious overkill, even if one seeks to provide an almost-always congestion-free campus network experience.
Ratios of different traffic classes
In the specific context of avoiding congestion for premium traffic, an additional parameter in the congestion equation is the ratio of non-premium to premium traffic. The larger that ratio, the lower the probability of premium traffic congestion on average --although the specific topology and usage must be examined to understand peak behaviors. Reducing the ratio of premium traffic is a function of eligibility criteria, e.g. subscription to the premium service, specific application need, and/or user desire.
The bottom line here is that an enterprise net consisting of switched 10Mbps access connections linked by Fast and Gigabit Ethernet backbone links might well be effectively non-blocking, but as more and more users connect at 100Mbps, and run applications that need it (i.e. either very advanced or very dumb applications), then some form of demand shaping may be needed to avoid peak congestion for premium traffic, or some additional eligibility discriminant besides physical port subscription (e.g. application type, or TOS/DS bits) might be needed to determine which packets actually receive premium treatment. Or combinations. In all probability, the 80-10 rule will apply to desktop connection speed. Most people will be well-served by switched 10 for several more years; a relatively small fraction will have a legitimate need for much faster speeds. Opinions vary on how that demand curve will evolve over time.
If pure "over" provisioning (no attempt to avoid congestion via demand shaping or admission control) is deemed insufficient, i.e. congestion is expected, then the campus network designer must choose among demand control strategies such as the following:
The foregoing approaches are listed in order of increasing complexity and management overhead. Whether the frequency of congestion on a well-provisioned campus net will be sufficiently low to forego the added complexity of quota enforcement or feedback-based demand shaping remains to be seen. If faster connection speeds and growing usage lead to on-campus congestion even with a well-provisioned backbone, the question becomes "what is the least-complicated demand-shaping technique that will do the job?"
The role of traffic policing.
Traffic policing is a way of enforcing a quota on one or more senders. The technique involves comparing incoming traffic against a pre-defined profile or specification and dropping (or downgrading) packets that are "out of spec". It is specifically targeted at controlling traffic peaks. Reasons traffic policing could be important in a campus/enterprise net include:
Policing is generally considered a "must have" for implementing QoS on wide-area networks; however, its importantance or effectiveness for eQoS is harder to assess. Some routers already support it, and if the capability becomes generally available, with acceptable performance and manageability characteristics, it is likely to be widely used.
Congestion within protected classes.
In an environment where there are different classes of network service, it is important to distinguish between the case where there is insufficient total capacity for all of the offered traffic, vs. the case where each class is allocated a portion of the total capacity, and there is contention within one of those classes. For example, if the problem is specifically loss or delay of high-priority traffic, one may need to target a demand control technique at that specific class. Alternatively, one could change the eligibility equation, i.e. the ratio of those who are eligible to request/generate high-priority traffic (vs. those who are not) by, say. increasing the price of subscription to the high-priority service. Implicit in this model is the idea that multiple classes of service are not likely to be served via simple priority queuing. More sophisticated queuing algorithms are needed to prevent any one queue from being completely starved of service, with resulting packet loss for that service class. Even the best-effort queue had better get reasonable service if angry mob scenes are to be avoided.
What about servers?
Most of the time we think of traffic flows and network congestion from the perspective of the desktop computer user. Servers represent a somewhat different problem than desktop systems in that they generally don't initiate traffic flows... they respond to requests. Usually the response contains much more data than the request. Under what circumstances should responses from servers have packets marked for priority treatment? In the absence of a receiver-based QoS reservation and compensation system, the server owner would need to take responsibility for providng excellent performance to clients, either via premium subscription, traffic charges, programatic capacity allocation, etc. One simplistic approach that might just work on campus: If incoming requests are marked for preferential treatment, then configure the server to mark responses in the same way. Another choice: Make the decision based on the type of server app, and if it is, for example, a streaming content server, then mark outgoing packets to request preferential treatment. This could be done either in lieu of or in addition to a priority boost based on a premium-port subscription.
What about incoming traffic?
Trying to decide which packets originating on campus desktop and server computers deserve to receive priority treatment is hard enough... deciding what to do with incoming packets (coming from outside the campus) that are marked for priority treatment is even harder. We presume that in most cases there is not going to be any way to charge the sender for high-priority traffic, though there may be a settlement arrangement with the external network service provider wherein inbound and outbound traffic offset each other. However, UW is currently a net consumer of commodity Internet traffic, and regardless of settlements or cost model, something must be done with those packets. We shall return to this issue later.
There are some networking truisms that relate to QoS design. Some of them include:
Guaranteed reservation vs. Preemption. QoS is often discussed in the context of providing bandwidth and/or delay guarantees to applications. At the same time, there is often discussion of priorities and pre-emption. The typical scenario described is that a CEO (or nobel laureate) needs to make an important presentation, and there are too many bandwidth guarantees already booked for the same time. Guess what? Somebody with a "guarantee" get's pre-empted.
Sender vs. Receiver control. Most of the QoS literature describes mechanisms that permit an application with data to send to reserve network resources. However, in many cases the sending station is not in the best position to make a request for privileged treatment. To illustrate this point, consider a web service accessed via a network with differential charging for different service levels. In this case, the receivers of the data are the ones with the incentive for paying extra to receive the web data more quickly. The same would be true of live or on-demand media servers. Mechanisms for handling receiver-initiated reservations have been proposed, but they are a bit more complex.
Simplex vs. Duplex channels. Collaboration tools require full-duplex communication channels. In a QoS environment, it doesn't make much sense to arrange for the session initiator to have preferred treatment for packets sent, while other participants have only a best-effort path back. However, arranging for bandwidth reservations in two directions, often with asymmetric routing, greatly complicates the problem. Even imagining a suitable policy database schema for this problem is non-trivial.
Busy signals vs. getting through. People are used to busy-signals in the telephone system when the called party is already using their phone. Less frequently, phone users experience circuit-busy signals, but the concept of "circuit busy" does not yet exist in the Internet. Moreover, in the Internet with multiple clases of service, a "circuit busy" at one level of service does not preclude attempting to communicate on a "best effort" basis. A hard QoS request that cannot be satisfied at the moment is the Internet equivalent of a busy signal, and almost certainly when confronted with an "Internet busy signal" many will wish to attempt the session on a best-effort basis.
Subscription vs. session pricing. A corollary of the above is that if premium service were to be charged on a per-session basis (ala telephone toll calls), then Internet users would often try a "best effort" "connection" first, and only if the current network conditions precluded adequate performance would they pay for a premium session. Therefore, it is widely held that a per-call-reservation QoS pricing model will not work very well, and users will need to pay for the right to access premium bandwidth on a subscription basis, that is, whether they use it or not. But in the subscription case, there must also be some incentive to not use the premium bandwidth all the time, or the economics may again fail to add up.
Per-flow state vs. scalability. Increasing peak bandwidth requirements and ever-increasing aggregate bandwidth requirements continue to stress both enterprise backbones and national backbones. The number of flows a backbone node will see is a function of the number of end-systems served. Some QoS schemes require routers to maintain per-flow state. Clearly this becomes more difficult as the scope of the network --the number of end-systems served-- grows. A solution that might be tractable in an enterprise network (in terms of per-flow router state) might not work on a national scale.
Differentiated-services vs. differentiated-pricing. The two concepts are independent. It is possible to offer either one but not the other, or it is possible that two might be linked, as our normal sense of equity would suggest.
Multicast. Multicast intersects with QoS, especially in the domain of multimedia and collaboration tools. Use of multicast technology to distribute the same signal to many destinations without replicating the stream multiple times is a boon to network efficiency, but can complicate the QoS problem. For example, different clients may have different bandwidth requirements, or different users may have different privileges with respect to accessing premium bandwidth. The already complex QoS policy space becomes truly awesome when overlaid with the technical complexities of multicast distribution.
Having end-systems negotiate with the net for reserved bandwidth is theoretically a Good Thing... but such a scenario has a darkside. For example, bandwidth reservation has the following less-than-desirable implications:
Some useful questions might include:
LANs and WANs have some opposite characteristics that are relevant to how one might choose to implement QoS in an enterprise. In particular:
With a network based on switched Fast Ethernet connections at the edges, and also Fast Ethernet connections to routers, it is quite possible that the enterprise core will become the biggest congestion point within the campus net. The implication for QoS design is that IF congestion is less likely at the edges of the campus network, it may not be necessary to have complex QoS-aware edge devices, since QoS mechanisms generally only affect packet handling when there is congestion.
The purpose of this section is to identify characteristics of an enterprise that will influence the type of QoS solutions needed.
The University of Washington is not unlike other billion-dollar-per-year enterprises, except that in addition to the normal Fortune 500 information technology concerns, UW also operates two hospitals and has many thousands of students wandering about seeking enlightenment.
At the University of Washington, the Computing & Communications organization supports:
70,000 accounts
40,000 end systems
2,000 modems
50 remote sites
We operate an IP-only backbone that currently handles nearly 500 Gigabytes/day with a doubling time of three years. Incoming border traffic from the Internet is now peaking around 40Mbps, with a doubling time of 1.3 years.
UW was a founder of NorthWestNet, one of the original NSFnet regionals, and for many years provided NOC services to its successor organization, Verio Northwest. UW also designed and operates the Pacific/NorthWest Gigapop, the Seattle Network-to-Network Access Point (SNNAP), which is a local-exchange point for ISPs in the area, and a statewide K20 network.
Our campus constituency includes teachers, researchers, students, administrators, and clinicians. UW is not an exception to the rule that the middle name of every academic department is "autonomous".
In the context of Internet 2, we see the following application pressures:
Some have also suggested that, lest anyone really believe that we can provide enough capacity in a campus net to keep everyone happy, the network version of the Quake game is capable of consuming enormous amounts of bandwidth, and may indeed be the precursor of some mainstream "advanced applications". These would presumably fall under the "collaboration" category above.
Delay and delay variation (jitter) are among the most important network performance characteristics, especially for full-duplex audio applications that are crucial for collaboration tools. Here is a listing of selected apps by (more-or-less) increasing sensitivity to delay:
Streaming multimedia is not included above because receiver-side buffering can often mask the network latency. Of course latency is very important for any interactive control information, such as "pause" or "rewind" of the streaming media. Note that there is no direct correlation between delay sensitivity and bandwidth requirements.
One would like network service, including premium service, to be transparent to the user. It should "just work", without users having to think about it. This has been an attainable goal for single class-of-service (best effort) networks; it remains to be seen how user-transparent a multi-service-class network can be. In some designs, where forwarding priority is based on TCP/UDP port numbers, the transparency goal can be achieved --provided that the application in question is one for which global configuration has already been done. Similarly, if the policy design for an advanced net is based soley on a port subscription fee for premium service, this too can be transparent to the user --except for the billing part, of course. However, there are definitely scenarios where users might have to take some specific action to obtain premium service for a session. Here are three examples:
In the first case, the premium service cannot be user-transparent because the user must make a value judgement about the specific activity or task at hand and whether it is worth using up their premium quota or paying for the premium service. (One can imagine that more privileged or well-heeled members of an institution, when confronted with such decisions, might simply configure their desktop to always seek premium service --at least for a particular set of applications.)
In the second example, the setup for the demo is likely to be very involved and require the participation of many people. Not only will this event not be user-transparent for the participants, it is possible --nay, likely-- that non-participants will be adversely affected (if significant fractions of heretofor best-effort bandwidth is suddenly sequestered for the demo). We conclude, therefore, that such events are the very antithesis of transparent network services.
Example three obviously requires user action. Whether this particular scenario is going to be commonplace is in dispute, however. We'll return to the topic in the section on reservations and scheduling in the following chapter.
Another dimension of usage has to do with eligibility for access to premium bandwidth. Possible scenarios include "first come, first served", "whoever can pay", "designated program/project participants", and "anyone above a certain station in life". Or combinations of the above.
Does the 80/20 traffic locality rule still hold?
Conventional wisdom is that the web has turned things upside down, and most traffic to desktop systems originates off-subnet. Without doubting that the web has had considerable influence on traffic patterns, we suspect that the picture is far more complex, with units operating local workgroup or departmental servers continuing to see intra-subnet traffic dominate, while those relying on central or external servers seeing interor off-subnet traffic dominate. And departments which have their own servers and are also split across subnets tend to complicate the measurement of these trends. But it is essential to understand these traffic patterns in order to properly provision the network and to be able to anticipate the places in the network where there is likely to be congestion, and therefore, a QoS issue.
In a QoS-enabled network, how smart must the edge switch be?
This question has important cost implications, and it depends in turn on several other questions:
If it were the case that downstream traffic (destined for the desktop) seriously outweighed the amount of traffic originated on the desktop, then one could argue that for any reasonable provisioning level, adequate to the downstream traffic load, the smaller amount of upstream traffic could be easily accommodated with low probability of congestion. Therefore, in this scenario, the first congestion point a packet leaving a desktop system is likely to encounter would be the subnet router interface. This scenario is attractive because it suggests that most of the QoS complexity in an enterprise network can safely be relegated to routers, and the edge switches don't need to be very smart, meaning that they can be cheap (i.e cheaper than they otherwise would be.) Intuitively, the hypothesis that most desktop systems will consume way more packets than they produce, and that consequently most subnets will be net consumers of traffic, seems obvious, even if one allows for desktop conferencing.
There is only one problem with that analysis: it is not supported by empirical data. On the UW network, there are many subnets that are net producers of traffic. It may be that the desktop hypothesis (most consume way more than they produce) is still true, but the existence of departmental servers exporting information tends to undermind the subnet hypothesis --which is the important one with respect to QoS provisioning. If packets from a desktop collide on their way to a router with those from a local server exporting, say a web or ftp site, then we still have an in-subnet congestion issue even if the desktop system itself is a net importer. That means a QoS-enabled network may need more expensive edge devices (or, if not "edge devices", at least more expensive building distribution switches) in order to apply policy preferences to certain kinds of traffic. It also suggests that those institutions which, for organizational reasons, tend to centralize their servers, or otherwise keep them on separate subnets, away from the desktop population, may be able to build a QoS-enabled network at lower cost than organizations where there is widespread use of departmental servers exporting data off-subnet. (Servers whose clients are local to the same subnet may or may not be an issue, depending on subnet provisioning.)
As mentioned in the previous section, there are a lot more edge devices than core devices in a campus net, so one would like the edge devices to be as inexpensive as possible. Many vendors offering advanced high-speed switches sell them in two forms: one with layer-3 functionality, and one without. Not surprisingly, the version with L-3 functionality is more expensive. This observation is the basis of the concern about complexity at the edges; however, a few multi-layer switch vendors have adopted the Alaska Airlines tagline "For the same price you just get more" and include both L-2 and L-3 functionality at a single aggressive price. So it is possible that edge complexity might prove to be less of an equipment cost concern and more of a configuration complexity and management concern.
Our bias is that within a campus LAN, it is plausible to rely on adequate provisioning plus differentiated queuing based on privilege, application need, or user desire. However, "no network should be an island" --regardless of how tempting that might be to administrators dealing with hackers-- and it is less likely that these same techniques will offer an adequate solution to the wide-area problem where adding capacity is generally more expensive. Since the interface between the campus network and wide-area links can have implications for the campus network architecture, and the ultimate goal of QoS mechanisms is to provide an end-to-end solution, it is important to consider the campus border router boundary briefly.
Kinds of wide-area connections.
There certainly may be others, but we'll focus on three:
The way premium service is packaged and priced by the national Network Service Providers (NSPs), be they commercial or research, has significant implications for campus QoS design. For example, the NSP might offer premium bandwidth in the form of a separate (virtual?) circuit, or as an allocation within the same best-effort channel. It might be charged based on a committed access rate and associated traffic threshold, or by peak bandwidth. In a research network consortium, it may not be the case that premium bandwidth use is directly recharged to the using institution, but that will surely happen in the commercial Internet. Therefore, the institution must decide whether to make premium wide-area bandwidth a core-funded allocated good, or to pass the incurred costs directly back to the end-user.
Network nirvana is considered "integrated services" --wherein all types of communication services (voice, video, and data) all share a single channel. Only a few network managers have aspired to fully integrate all communication services within a campus over a single infrastructure in the near-term. Most have viewed their separate data, video, and voice distribution systems as sunk costs that are working just fine, and haven't wanted to risk using relatively unproven technology for speculative economic gain. They also realize there is value in species diversity and some level of redundancy.
The wide-area case is a different story, however, because there are clear economic benefits to aggregating traffic over a single big pipe rather than leasing multiple smaller pipes. So in one sense, integrated services over wide-area links is old news. Many organizations lease wide-area links and then carve up the channel capacity among their voice, video, and data needs. You might think of these static configuration allocations as "long term reservations".
But this is usually done in the context of time-domain multiplexing (TDM) so even if a service is currently idle, the bandwidth allocated to it was not available to other services. So the real goal is a more flexible bandwidth allocation scheme so that bandwidth unused by one service becomes available for another. However, if this goal is achieved with less than 100% certainty that a given service will always be able to obtain its allocated bandwidth, a network manager might still choose a less efficient bandwidth allocation scheme (e.g. SONET multiplexing) in order to have the certainty that one service cannot interfere with another. Besides, SONET channels can often be procured in high-availability (rapid failover) "protected ring" configurations.
UW campus backbone traffic, currently approaching 500GB/day, is doubling every 3 years. In the past six years, Ethernet technology has gone from 10 to 1000 Mbps, an increase of two decimal orders of magnitude, while campus backbone traffic increased by a factor of four at UW. These numbers suggest that it should be possible to add campus network capacity fast enough to keep up with average demand. That's the good news. The bad news is that a) there exist bottlenecks in the current 10Mbps shared subnets that may be artificially constraining demand, b) if Ethernet traffic is indeed self-similar, aggregating it will not even out peaks, it will exacerbate them, and c) we are on the verge of new application paradigms, e.g. desktop video, that may invalidate any projections based on historical data. Since no one really knows how much bandwidth will actually be needed by different classes of users in the future, only time will tell whether raw capacity will keep supply ahead of demand, but there is reason for encouragement.
UW Internet traffic, currently peaking at 40Mbps inbound and over 20Mbps outbound, is doubling every 1.5 years. This is particularly worrisome, not just because of the rapid doubling, but because unlike the campus net, national Internet service providers have been moving away from flat-rate pricing to usage-based pricing (ostensibly as a favor to customers who don't use very much.) Many institutions may decide to limit core-funding of this ever-increasing cost and instead seek methods of reflecting any usage-based charges back to those who incur them.
This document was originally written in early 1998, and revised throughout 1999. News flash: Today's data networks are not ready for QoS, and it will take "forklift upgrades" to get them ready. Perhaps worse, the same is true for today's end-systems, i.e. the computers themselves.
The prevailing state of network evolution at UW and elsewhere is collections of shared 10Mbps Ethernet segments, linked by routers. What's wrong with this picture? From a QoS perspective, quite a bit. Shared Ethernet segments use a media access discipline (CSMA/CD) that introduces delay variation (jitter) as a function of the number of sending stations contending for the medium. Since these shared links are inherently half-duplex, traffic to and from the same station can collide and thereby exacerbate the jitter problem. Prevalent desktop operating systems are not noted for their low-latency or low-jitter properties, either. Indeed, the statement has been made that prevalent desktop systems lack the clock resolution to do adequate traffic shaping, so we may be looking at forklift upgrades of both network and end-system components before adequate QoS is achieved. Maybe more than one.
But on the network side, there is some good news in that everybody's already switching to switches. This widespread replacement of Ethernet hubs (repeaters) with switches is sometimes called "microsegmentation" because it reduces the number of nodes on an Ethernet segment from hundreds down to as few as one station per switch port. This trend has two motivations: performance and security. Performance is increased because there are fewer stations contending for the same bandwidth; security is improved because traffic is isolated so that it is only visible to the station(s) on the one switch port, thus reducing opportunities for password sniffing.
For collaboration tools, e.g. desktop conferencing, reducing delay and jitter is extremely important, and this calls for full-duplex connections. Although current 10Mbps and 100Mbps Ethernet switches and interface cards are capable of full-duplex operation, there seem to be some configuration and interoperability challenges. For example, auto-negotiation is a problem in buildings with category three cableplants, since the negotiation will attempt to land on 100Mbps even if the cableplant is marginal at that speed. Also, many 10Mbps NICs default to half-duplex and don't provide any easy or obvious way for end-users to change that. Worse, if one end of a link is configured for half-duplex, and the other for full-duplex, they interact badly. Connectivity occurs, but with a high error rate. The result is that the user sees poor performance but has no clue that there is a configuration problem. To reduce the risk of misconfiguration, sites may decide to "go with the flow" and configure switch ports to be half duplex, to match the default of most NICs. From a QoS perspective, this is a problem.
In universities with buildings more than a decade old (i.e. almost all of them!) there is also a problem with the wireplant... The defacto-standard version of Fast Ethernet, 100BaseTX, does not work on older "category 3" wireplants, and the version that does, 100BaseT4, was never well-supported by vendors, and is now largely irrelevant because of the TX momentum. So upgrading from 10Mbps to 100Mbps may be non-trivial in older buildings because the wireplant needs to be upgraded too, not just the electronics. Moreover, if switched 100Mbps service becomes the prevailing standard, as opposed to switched 10 service, this puts more pressure on the capacity of the other levels of the enterprise network hierarchy, and calls for Gigabit Ethernet uplinks from the 100Mbps switches in order to aggregate traffic from multiple stations with acceptably low probability of contention. These GE links (between closet/edge switches and building-entrance room switches) will need to be fiber, and that also increases the cost of upgrade. Finally, the longer GE links will require single-mode fiber, whereas previous campus network technologies used multi-mode fiber.
The IETF DiffServ working group has now agreed upon a specification for how TOS bits will be used, and routers implementing the spec are due Real Soon Now. Similarly, traffic policing and shaping capabilities are expected soon.
Reasonalby priced Ethernet switches are only now becoming available with the features needed to support a next-generation enterprise network. Examples of useful features include:
In some cases, vendors will require their "Layer 3" software functionality --often at extra cost-- in order to support some of the features that may be needed in the edge switches.
The purpose of this section is to identify the characteristics of a satisfactory QoS solution, and try to answer the question "How will we know when we get there?"
There are three constituencies that have a stake in the type of QoS mechanism chosen for an enterprise: users, application developers, and network administrators.
So what do users & app developers want? Need?
Both developers and users want infinite bandwidth with zero delay, at any instant. What they need is a completely different question, but this much seems clear:
What are the relevant user satisfaction criteria?
Those that are often cited relate to thruput and delay (and delay variance, or jitter), but in a QoS-with-reservations system, we need to add busy signals to the list. Any system that offers its users a significant number of busy signals may be deemed a failure.
What do network managers want?
Above all, network managers would like an enterprise network QoS design that minimizes cost while keeping their users happy by providing good performance and very high reliability and availability. Said differently, they want to minimize the number of performance and availability complaints from their user community, and minimize the number of complaints about cost from their boss. Clearly, the ability of a QoS scheme to provide the desired network properties to applications, without undermining network availability, will affect the number of user complaints. Containing costs, on the other hand, will require careful consideration of several administrative issues, including:
It's conceivable that mechanisms designed to avoid congestion may sometimes prove inadequate. What then? Any viable solution must balance the needs of both premium and best-effort users:
Say the capacity of the potentially-congested link is Z bps and the expected usage by best-effort/low-demand apps is X bps and the expected usage by priority/high-demand apps is Y bps. Now if X+Y > Z, how do we want the router feeding the congested link to behave?
We would expect the router to give preference to priority packets until some threshold (fraction of Z) was reached after which it would service the low-pri queue for awhile (if there was pending low-priority traffic). If the threshold is 100%, best-effort traffic could be completely starved, therefore, one might choose a lower threshold in order to allow some best-effort traffic to survive.
We claim that if premium traffic should ever displace (cause to be dropped) more than, say, 10% of the best-effort traffic, the network manager has a big problem (and this number is probably high). Similarly, if more than a few percent of the high-priority requests fail to result in adequate application performance, the network manager is again toast. This conviction has profound implications for QoS. It suggests that network manager survival --much less, success-- is unattainable unless the gap between bandwidth supply and demand is relatively small, and in a world of potentially infinite bandwidth demand, this means that strategies for either allocating available bandwidth or shaping/moderating demand to fit available bandwidth are not optional niceties; they will make the difference between success and failure. The QoS techniques available to us can address the problem of congestion due to instantaneous peak demand, but they cannot mask any serious and persistent mismatches between supply and demand.
How big a problem this is going to be depends a lot on how big a chunk of bandwidth is needed for a particular application, relative to the total available capacity. For flows that are small relative to the total, short-term reservation mechanisms may not be needed, as those demands should be accommodated via normal capacity planning and traffic engineering. On the other hand, if a particular application needs large amounts of bandwidth relative to the total available on a congested link, then the network manager better be scouring the countryside for some fresh bandwidth, or planning on doing some serious expectation-setting for when those competing with the mega-app find their packets falling on the floor or their reservation requests being denied.
Distance education has introduced into the data networking lexicon the concept of "scheduled bandwidth". The idea is that regularly scheduled classes will require regularly scheduled bandwidth, and likewise, it is often said that important live events will require a mechanism for reserving network bandwidth at the appointed time, lest the featured speaker be reduced to Internet noise and "snow". Implicit in this view is the assumption that the network will have insufficient capacity for handling all of the applications using it at any given time, or at least during peak usage times.
But to validate this hypothesis, we need to ask two questions:
Moreover, we suspect that the bandwidth needs for scheduled events will be relatively small compared to needs for all of the other things going on, especially demand-video applications. However, there may still be situations that require "assured" bandwidth for a future event. There are a range of strategies for achieving such a goal. One is an advanced reservation strategy... but this technique involves taking away bandwidth from other users, perhaps even others who themselves thought they had their own bandwidth assurances. If there is sufficient bandwidth available so that only low-priority delay-insensitive traffic is affected, then the reservation wasn't necessary, and if there wasn't, then less privileged users will be unhappy about the network's performance.
Another alternative is to actually "create" new bandwidth, at least for the duration of the event, via contracts with telecom/Internet providers. For example, AT&T has recently introduced some "Managed Bandwidth" services for just such situations. Sometimes organizations have the ability to reallocate bandwidth that is already under contract. For example, in the case of enterprise "integrated voice/data/video" networks which are based on statically allocating different amounts of bandwidth on a TDM channel to each application, it may be possible to re-apportion the amount given to the three separate services in order to provision a special event. Of course, the disadvantage of such integrated nets is that bandwidth allocated for one app, say video, is not available for other purpose when not needed for video except by static re-allocation. On the other hand, the cost of managing short-term reservation paradigms may exceed the cost of increasing capacity enough to not need reservations. At least in the campus net; maybe even in the wide area.
If an advance reservation model is to be used to provide assurances about future bandwidth availability, there is a question of reservation duration. Unlike scheduled lectures, the duration of many sessions is unknown and unknowable in advance. For example, in setting up a flow for a desktop video conference, what should be the length of the reservation? Router state to support a reservation can be timed out after a flow ceases for some interval, but this technique is not sufficient to provide the capacity guarantees often expected from a reservation-based QoS system. (If you don't know when one reservation will end, how do you know if there will be sufficient capacity for the next one to begin?)
The name of the game is bandwidth creation and allocation, but it's important to keep in mind that there is a wide spectrum of time-scales in which to create or reallocate bandwidth, from years (for building new physical infrastructure) to microseconds (for packet-by-packet decisions).
One of the ironies in this discussion is that telephone service is often used as the defining metaphor for Internet QoS work, yet the two are opposite in this regard: most people would not think the world had improved if telco congestion problems forced customers to reserve bandwidth in advance of their phone calls in order to reduce the probability of getting a busy signal. (Apparently in the early days of telephony, such reservations were needed to make long distance calls, and having moved beyond the need for reservations is generally viewed as progress!)
So do we need advance reservations or not??
Given greater peak demand than current maximum capacity, one might try to steal some capacity from the lower service levels and hope they don't notice. If the traffic mix is such that you still don't have enough head room after "borrowing" some bandwidth from the best-effort crowd, then the next best hope is to shape the demand; smooth it out; i.e. to move some of the demand to an off-peak time. This might be a nanosecond adjustment, as in traffic shaping, or a daily peak (e.g. modem usage just after dinner). Scheduling (advance reservations) is only one approach to this problem.
Quotas in the form of shaping and policing seem to be widely accepted as a good way of dealing with very short-term peaks. Feedback has been shown to work for shaping long term peaks (as well as providing revenue for adding capacity, if the feedback takes the form of an invoice). Quotas in the form of subscriptions/committed access rates also appear to be a viable way of provisioning for medium/long time scales. So what would be a scenario that demands the use of scheduling?
In an effort to understand when reservations might be a good solution, let's first identify situations where scheduling may be problematic. For advance reservations to make sense, we claim:
Translating to specifics:
Many organizations have some experience managing conventional videoconferencing systems. In many cases, the bandwidth needed for the video conference is a significant fraction of total capacity available to the remote site. For example, 768Kbps out of an available T1 (with the other half often reserved for data.) This kind of a scenario doesn't leave much room for on-demand use... clearly reservations are appropriate in this case. On the other hand, if this event was using 768Kbps out of an OC12 connected to the Abilene Internet2 backbone, even if one of hundreds of similar sessions, I can't imagine that we'd want to be worrying about reservations... we'd be watching the OC12 utilization on a continual basis, and when offered load started to get close, we'd be trying to figure out how to add more capacity. In a market/commercial scenarioi, this might mean adjusting the (presumed) revenue stream from users needed to pay the NSP providing (and charging for) the premium service to make sure that we didn't run out. Similarly, even if we were running near the edge, if it was possible to add capacity for the duration of the session via switched public network services or managed bandwidth services, we'd probably want to do that rather than deal with reservations.
Contrast this with the scenario where most or all of one's Internet2 OC12 link was to be reserved for a big demo. If the OC12 is shared with on-demand premium traffic and/or best-effort traffic, such a reservation will result in serious mutiny by those uninvolved in the demo --unless everyone understands that the I2 link cannot be depended upon for production use, but that is not realistic considering the current state of routing technology, which almost guarantees that all traffic between a given pair of institutions (both production and experimental) will use the same path.
If a major part of the OC12 capacity is dedicated to scheduled bandwidth requests only, then the reservation scheme will work... but: if reservations are not needed very often, this is big waste of bandwidth, and --as others have observed-- such large-scale reservations are likely to be both rare and require coordinated effort of lots of people, so they are effectively reservations by massive manual configuration.
A case can be made that most premium bandwidth in Internet2 will be consumed by relatively smallish (compared to total capacity) on-demand AV streams, with indeterminant duration, interspersed with occassional extraordinary demands. And big demos will almost surely involve many people and much manual reconfiguration. So is there a case for a sequestered "advance reservation channel" to accommodate lots of "mid-size" requests of determinant length? Or will the frequency of such requests be low enough to not warrant either the sequestered bandwidth nor the reservation machinery?
With the advent of IP telephony and video, the attraction of integrated services is resurgent. There are a couple of points to be made here:
We can conceive of a network design where the primary emphasis is on relatively persistent reservations, essentially a segregation strategy that allows for different services or service classes to be kept separate, but using modern queueing technology so that bandwidth unused by one service is available to others. For example, consider a model where routers (or layer-3 switches) support multiple queues, say, for IP telephony, IP conferencing, (other) high-priority data, and best-effort data. Suppose further that the router supports a queuing discipline where each queue is serviced, before going to the next queue, for a maximum of 1/4 of the output link capacity. This model provides:
An important observation is that gateways to traditional transport paths for POTS and videoconferencing will certainly be part of the enterprise network architecture, and these gateways will be linked in some way to the campus IP border routers. In some cases the gateway will "de-mux" an integrated traffic stream from off-campus onto the separate infrastructures for voice, video, data on-campus, and in other cases the gateway will take voice or video streams from the campus IP data net and connect them to traditional wide-area transport services for voice or video.
Implementation of multilevel allocation/prioritization
It is possible that more queues and more sophisticated algorithms could be used to provide prioritization within long-term reservation categories. But there is a possible problem with the number of bits available to represent distinct service classes plus priorities within service classes. For example, the 802.1p/Q specs define three priority bits, which isn't very many for this dual role. There are a few more bits available in the IP TOS header field, and the IETF DiffServ spec defines some TOS field code points for local use, so perhaps these can be used to map a sparse hierarchy of priority policies into the available codepoints.
The advent of tag switching, or Multi-Protocol Label Switching (MPLS) may provide an effective mechanism for implementing nested allocation policies. MPLS essentially provides a way of implementing virtual circuits in a pure IP environment, and seems entirely complementary to the intended use of TOS bits as specified in the DiffServ specification. This approach would imply that router vendors offer the appropriate queuing disclplines necessary to allocate a certain percentage of channel capacity to a particular MPLS virtual circuit, while respecting the TOS/DiffServ prioritization bits on packets within each MPLS virtual circuit flow.
A cornerstone of much QoS work is the assumption that bandwidth/delay requests must be authenticated, since network managers will never trust end-systems. While it is certainly true that network managers will not trust end-systems, it's worth exploring the solution space a little more completely.
As discussed earlier, privileges, quotas, and costs can all be associated with a variety of different parameters, e.g. user ID, physical port, MAC or IP address. The principal advantage of using the identity of the user is that it affords location and computer independence. That is, if privileges are associated with a user, those privileges can be used regardless of what computer the person happens to be using or what physical port that computer is connected to. On the other hand, this approach implies that the user must authenticate even if they are using their "normal" computer/port. Although logging-in is a normal requirement for accessing many enterprise resources, it is still relatively unusual to require authentication to access the network "dial tone" from one's primary office location.
Experience with the phone system suggests that a viable model is to base "normal" access on physical port alone (no authentication needed) while providing authenticated access from alternate locations (via phone cards, etc). The moral equivalent for the enterprise data network would be eligibility control based on physical port for one's "normal" computer, with eligibility control tied to authenticated layer-2 network access from alternate locations. The alternate locations might be drop-in/plug-in labs, or dialup PPP links, or Virtual Private Network (VPN) connections. Alas, while there are a dozen different ways to implement layer-2 network authentication, none of them are very elegant.
In situations where user authentication is desired, the authentication process must result in a trustworthy mapping between the user and bits in the packet that network devices can rely on. This is usually done by establishing a (transient) binding between the user and the source IP address.
Does traffic shaping require user authentication?
It does not. Traffic shaping by the sending system and shaping or policing by network nodes may be based on the type of application or the originating node, to offer two alternatives to user-based shaping.
Is premium service possible without user authentication?
Yes, it is. User identity is only one basis for marking certain packets as privileged. As previously noted, other approaches include associating privilege with a physical port (via static configuration of the edge switch), and/or prioritizing based on app/user "need" or "desire" using TOS/DS bits and perhaps with post-audit feedback based on usage.
User authentication, while in general a Good Thing, is neither free nor without tradeoffs. Even ignoring the cost of the site's authentication infrastructure, which presumably exists for other reasons, its use in the network must be examined carefully. The finer the granularity of the security checks (e.g. per-packet, as opposed to, say, per-session), the greater the performance hit on the forwarding function, and perhaps even reliability suffers (if the auth data is external and/or very volatile). On the other hand, the larger the granularity of security checks (e.g. per-session) the higher the risk of spoofing or hijacking connections. Moreover, if the QoS scheme considers application need as important as user privilege, then it should be noted that user authentication does nothing to guarantee that "application need bits" are set appropriately.
Possibilities for when authentication might be done include: when first connecting to the network (layer-2 auth), when one does a normal session login for access to other resources, and when a particular application is initiated.
An alternative to user authentication would be machine authentication. This is sometimes done by pre-registering MAC addresses and controlling the assignment of DHCP addresses based on that registration. This provides some level of access control to the network infrastructure, especially useful when there are "drop in" labs with Ethernet connections or 802.11 wireless access nodes. However, machine authentication has some drawbacks:
Conclusion: Many of our eQoS goals can be achieved without user authentication, but there are likely to be some situations where it would be useful to base premium service eligibility decisions on user identity.
With the advent of the IEEE 802.1p/Q standards for prioritization and VLANs, and more recently, the DiffServ IP spec, it appears that virtually every modern Ethernet switch will support multiple queues. Although many of these switches will be used in places where congestion is less likely to be a problem, it still seems like a worthwhile requirement to be able to use this multiple queue capability, unless doing so introduces excessive complexity into the system.
A key question is: which characteristics of an incoming packet can be used as the basis for queuing decisions. The likely possibilities include:
In addition, high-end switches could potentially participate in an RSVP negotiation with the end-system.
Switches also vary in how many output queues they support, and what capabilities they have for setting/modifying packets (e.g. over-riding the TOS or 802.1p/Q bits to control how the packet will be queued in subsequent hops.)
Which options are implementable?
As a reality check, we reviewed the class-of-service capabilities offered by a modular switch product from a mainstream vendor. It offers two output queues per port, and allows for the priority decision to be made on the basis of:
Notably, this particular switch does not support the seemingly obvious choice of prioritization by the application's IP port number. However, as previously noted, the IP port number strategy is fraught with limitations (e.g. dynamic port assignment in H.323, IPSEC encryption), so this is probably not a huge loss.
Who do you trust?
Another key question is how much control the end-system and its applications have over the queuing decision. What if end-systems were permitted to mark any or all packets for priority queuing (either via 802.1p/Q bits or via TOS/DiffServ bits)? If such a laissez-faire approach to prioritization is taken, what will prevent end-systems/apps from hogging the high-priority queues? In the absence of some kind of network-based prior-restraint mechanism to verify the user/application/device/port eligibility for priority service, one might anticipate a disastrous outcome, where "disaster" is defined as "priority queuing" being over-used and therefore tantamount to yet-another best-effort service. However, prior-restraint or real-time eligibility validation is not the only way to prevent this disaster... post-audit or ex post facto feedback mechanisms discussed elsewhere in this document will also work.
However, even the idea of accepting end-system requests at face value without any feedback mechanism to moderate demand --though potentially perilous-- may still be plausible because:
NB: The observations above also suggest that TOS/DiffServ bits might not represent "user desire" since most users may not know how to directly manipulate them; rather, they may actually prove to be the more accurate indicators of "application need", if indeed those bits will normally be set by system calls included in a particular application by its designer. We will have to see what kinds of end-user QoS controls may be provided by operating system vendors.
If laissez faire usage or ex post facto feedback don't adequately moderate demand for preferential queuing, the next simplest strategy might be to mark incoming packets at the edge switch based on a subscription level associated with a physical port. (IP address of the end-system could also be used but would require more administrative complexity as computers are replaced or reconfigured.) In this case, it is important for the edge switch to be able to modify outgoing packets, perhaps using 802.1p bits and/or VLAN configuration to carry the premium port subscription information to subsequent nodes.
If the interior switches chosen are only capable of queuing based on 802.1p bits, and not TOS/DiffServ bits, it might be useful to have an edge switch that is capable of translating TOS/DiffServ bits into 802.1p bits. However, we expect that most switches capable of differential queuing will also be able to use TOS/DiffServ bits to implement a prioritization policy.
Finally, one can imagine (higher-end) edge switches fully participating in hard QOS mechanisms using RSVP, maintaining per-flow state, etc. This is not an option with many of the lower-cost Ethernet switches, and exceeds our threshold of pain for infrastructure complexity, but is included here for completeness.
Establishing a prioritization policy
In designing an enterprise QoS strategy that takes advantage of multiple queues in switches and routers, the various priority values associated with those queues must be associated with carefully defined policies. An example (mentioned elsewhere in this document) of policy dilemma that must be addressed in this design process would be whether or not a premium subscription packet from a delay insensitive packet (e.g. email) should take precedence over a delay-sensitive packet (e.g. voice-over-ip) from a normal port. Another example would be deciding where packets with IPSEC encrypted header info should fall in the priority hierarchy.
Different devices in the network may support different numbers of queues. For example, as noted above, some switches offer two priority queues, but other switches or routers may support eight or more queues. Accordingly, it is important to think thru how a prioritization policy would be mapped to all of the devices in use.
Although we've identified three different packet fields that may contain values useful for prioritizing packets (IP TOS, IP Port #, 802.1p/Q), not every device will necessarily pay attention to all of them. It is likely that IP TOS/DiffServ will prove to be the most important field, and that virtually all future devices will support prioritization based on it.
One approach to developing a prioritization policy would be to:
In short, think carefully about what each element of the infrastructure (edge switches, interior switches, core routers, border routers) should do with incoming packets of different priority with respect to queuing and setting priority-relevant values on output.
Above all else, it is imperative that the QoS mechanisms chosen do not adversely affect the overall reliability and availability of the network. Things that drive reliability down include:
The relationship between reliability and multiple dependencies can be subtle. Complexity is sometimes necessary to improve reliability, as in the case of dynamic routing protocols or other mechanisms supporting redundant paths. Proper distributed system design can reduce the affects of component failures, but there is still no substitute for simplifying the problem requirements in order to reduce the need for complexity!
So why the paranoia over accepted approaches to QoS? The network failure modes specific to QoS that might affect the ability to forward packets have to do with authentication and authorization. In the absence of hard QoS mechanisms, packet forwarding is based on 1) information contained within the packet, plus 2) the results of routing calculations, plus 3) router configuration information, e.g access lists. With hard QoS, forwarding decisions are also dependent on a policy database, plus authentication of any request for special treatment (which will typically involve a lookup in a different database, e.g. the Key Distribution Center, or KDC). In some systems, interaction with a third database for authorization or group membership determination might also be required.
In a high-performance network, it is desirable to make decisions affecting packet forwarding as infrequently as possible, for both performance and complexity reasons. QoS models are often based on uniform treatment of a "flow" --a sequence of packets comprising a "conversation"-- and end systems may wish to request special treatment for a particular flow, based on either privilege/price considerations, or the network needs of the application. Or a user may wish to reserve bandwidth at some time in the future for a particular application flow.
If one is going to differentiate treatment of flows based on information that is not self-contained within each packet, it is preferable to make the decision once at the beginning of the flow, rather than on a per-packet basis. The advantage with respect to performance is obvious; we claim that availability is also inversely proportional to how often a policy decision based on external information needs to be made. Carrying this logic further, having policy authentication or authorization decisions occur once per "session" would be preferable to once per "flow". And once per "port installation/configuration" would be the best scenario of all, from a reliability perspective.
A corollary of the above is that having policy information distributed across all relevant switches, so that forwarding decisions do not require going "outside the box", is a Good Thing reliability-wise, even if upkeep of that policy info is usually easier in a central database. If policy info is moderately volatile, it needs to be centralized to facilitate upkeep, but switches need to cache the info in order to achieve high performance and lower dependency on external devices (databases). If the policy info is extremely volatile, these techniques breakdown. At the other end of the spectrum, if the policy data is more static, it can be treated more like switch configuration data with no run-time dependency on external databases.
Conclusion: keep the QoS solution as simple as possible (but not simpler :). Different institutions will have different needs, policy frameworks, and financial frameworks. All of these will influence how complex the QoS mechanisms must be for them.
There are many aspects to network administration and operation, e.g. budgeting, purchasing, device configuration, IP address assignment, troubleshooting, client configuration support. The purpose of this section is to identify administration issues that are related specifically to different QoS strategies.
For any scarce resource, policy makers can choose to construct either a planned economy or a marketplace economy... or some combination. In the planned economy, the scarce resource is treated as an allocated good. Allocation quotas might be based on privilege, programmatic priority, or some notion of "fair share". This approach is similar to disk quota mechanisms and mainframe computer allocation strategies from times past.
But not everyone who is old enough to remember timesharing is anxious to relive those mechanisms. An alternative is a marketplace economy where users of a scarce good pay a price that is purported to have some relationship to the scarcity of the resource.
The two approaches are not mutually exclusive... allocation policies can exist within categories of service that themselves are selected by price.
Faulty Metaphors
Within the "quota/allocation" (prior restraint) approach to bandwidth management, the issue is: Who can do what to whom at what times, with respect to network capacity. Neither phones nor airlines provide the right metaphor. It's often said that the goal of Internet QoS efforts is to provide telephone-like service. However, telephones only provide one quality of service (a switched circuit dedicated to each conversation), and if network resources are insufficient at the time of the call, there is no alternative but to try again later. In contrast, Internet users, accustomed to a single best-effort service, will more-than-likely want to fall back to best-effort service when confronted by a busy signal for a premium service level. And while airline reservations for different service classes seem to offer an obvious parallel to enterprise bandwidth management, we claim that the comparison is weak because the economics of over-provisioning a campus network are infinitely more favorable than over-provisioning an airline.
User-visible QoS characteristics
Some distinguishing characteristics of QoS mechanisms are:
-How many quality levels?
-Are there busy signals? Busy signal fallback to best-effort?
-Are there advance reservations?
-If there are reservations, is there pre-emption?
As previously mentioned, many delay-sensitive apps are full duplex, implying a need for bidirectional reservations, thus complicating the privilege-based policy/security problem.
Another slice on the QoS taxonomy has to do with admission control at congestion points. That is, whether an application will be given the resources it desires. Will that decision be made: -Via privilege/price or via application's need? -Via trust or policing?
Note also that the admission control decision might be binary (yes/no), with "no" constituting a busy signal for the application, or it might involve a negotiation where the "network" says to the application "you can't have X but I'll give you Y".
Congestion avoidance philosophies
Opinions vary as to which congestion avoidance approach(es) to emphasize. It's tempting to characterize the choices in these terms:
A planned economy with allocated goods (quotas) vs. marketplace with pricing
But that dichotomy doesn't quite work because quota levels might be established by price as well as privilege or central planning. So market pricing could apply equally to:
predictable payment for a particular quota level vs. variable payment based on usage
And quotas could be checked:
In that last case, there is presumably some penalty associated with going over the quota that translates either into increased revenue or modified future behavior. Moreover, we deal in social, as well as dollar, economies, so it is important to consider a variety of psychological factors in shaping demand for preferential treatment.
Perhaps there is some insight to be gained by this taxonomy:
From a network administrator's perspective, the real distinction among congestion avoidance strategies is whether they require case-by-case decisions to be made about the worthiness of an individual or project, or whether the policy problem is one of establishing reasonable pricing, after which, the (social or economic) marketplace is left to do its thing with little or no intervention. Another dimension of great interest to administrators is complexity of implementation and operation. For example, it's probably fair to say that post-audit packet counting is simpler than prior-restraint admission control schemes. Not unarguably better, just simpler.
Congestion avoidance philosophies aren't entirely mutually exclusive. One can imagine designs where several service classes are allocated specific amounts of capacity, and contention within those classes is managed via marketplace principles. Or vice versa.
The most extreme example of a marketplace philosophy would be a design where the only congestion avoidance mechanism --save perhaps nanosecondlevel traffic shaping-- was "behavior shaping via feedback", i.e. no eligibility or admission control. Imagine a world wherein users (or their end-systems/applications) are permitted to request preferred service whenever they wish; a completely laissez-faire approach. This strategy requires that an economic or psychological feedback control system exists in order to moderate demand. Often the feedback takes the form of usage billing, but other possibilities exist. For example, at UW we've had good success limiting "hogging" behavior in modem pools by sending ex-post-facto warnings that the person is using more than their fair share of the resource.
For comparison, a quota mechanism, such as committed access rate, based on subscription fees and tied to a physical port ID represents a solution that is probably comparable in complexity to a post-audit usage-based pricing solution, but one which offers the advantage of a predictable flat-rate cost structure for the user.
Is prioritization by application need hopeless?
In spite of the difficulties mentioned previously about trying to base prioritization decisions on application type, as indicated by TCP/UDP port numbers, it is still worth considering this possibility. Recall that there are four problems with using IP (TCP/UDP) port numbers: apps which use dynamic port assignment, possibility of subversion by cooperating users, potential that IPSEC will obscure the info, and the same app may have different needs depending on how it is being used.
If we assume that widespread use of fully-encrypting IPSEC tunnels is still a couple of years out, and that at least some delay or bandwidth-sensitive apps use a well-known port number, it might make sense to try out the idea of prioritization by port number... but I'm becoming increasingly skeptical that it will be worth the trouble. Rather, it might make more sense to focus on the use of TOS/DS bits by the application as a better indication of application need. While it is true that some vendors are contemplating user-accessible knobs to control setting the TOS/DS bits (and thus letting the user express their "desire" for preferred service), it is possible that inertia or ignorance will prevent this opportunity from turning into widespread abuse of network preferred service. That is, it may turn out that in most cases, the OS system calls implemented by the application developer will determine how the TOS/DS bits get set, and thereby provide a better basis for queuing decisions than the application's IP port number.
How, then, to make best use of differentiated queueing on campus if prioritization is essentially done by user/app request? The fear is that in the absence of demand-shaping feedback (i.e. cost), users will cause their systems to mark all packets as desirous of preferential treatment, and in the absence of eligibility/admission controls or quotas, those packets will in fact be given priority queuing, and the outcome will be yet-another-best-effort network.
True or False? There must either be an allocation/quota scheme, or there must be some cost associated with requesting high-priority service, otherwise all packets will become high-priority packets.
It doesn't take too much cynicism about human behavior to assume the worst here, but the arguments given in the "Who do you trust?" paragraph of section 04.6 offer some cause for optimism about a laissez-faire approach. Nevertheless, it's important to pursue the implications of unconstrained desire for premium service, if nothing else, as a contingency strategy.
Effective eligibility control
If a packet stream is eligible for premium service, by virtue of the physical port or user associated with it, should all of the packets from said user or port be marked as high-priority? In addition to the obvious policy/fairness aspects of the question, we need to worry about over-subscribing congested links and being able to optimize use of the campus switches. If the number of eligible ports or users is relatively small with respect to the total, additional controls (admission or behavior) may not be needed, but increasing the percentage of premium-eligible ports/users will eventually lead to problems.
The various methods for prioritizing packets (described previously) are not mutually exclusive, but may be combined to create strange and wonderful policy permutations. In addition, the decision criteria for packet prioritization (desire, privilege, need) are orthogonal to pricing mechanisms, which might coincide with one of them (e.g. privilege based on price paid) or might involve all three.
Ultimately, these policies need to map to bits in the packet being forwarded and/or policy database entries... Moreover, the policies and the bits must in turn map to different queues in the network devices.
Should the CEO's email beat your DVC packets?
If using both "privilege" and "application need" in the QoS policy matrix, one must confront conflicts and contradictions. One example: should delay-INsensitive traffic (e.g. Email packets) from a privileged user take precedence over delay-sensitive traffic (e.g. desktop audio/video conferencing packets) from a non-privileged user? The correct answer may have nothing to do with either logic nor technical considerations, but it is constrained by technical realities. In particular, the number of queues available in the chosen network switches. For example, with two queues available, it is likely that all packets from a premium port would take precedence over any packets from a non-premium port. In contrast, if eight-queue switches and routers were used, then finer grain policies would be possible, such as: high-priority packets from normal (non-premium) ports would take precedence over "normal" packets from a premium port, but high-priority packets from a premium port would take precedence over everything else.
Cost, price, and value: these are three independent concepts! Good networks are both important and expensive. Network costs on a single campus tend to be relatively fixed. That is, while operational costs are certainly recurring both because of salaries and upgrades, the cost does not change much due to variations in usage. This was also true for research networks, but there seems to be a trend in the commercial Internet services space away from the flat-rate traditions of the Internet to usage-sensitive pricing. Questions every network administrator thinks about include:
These questions bring us to the question of pricing, regardless of whether ones philosophical bias is toward quotas and allocation, or marketplace feedback, or trust in good behavior.
What are the network pricing objectives?
One objective would be to provide capital funds for adding capacity to the network. Another would be to recover transfer costs for external network connectivity, especially if those costs correlate to individual usage.
A third goal might be to moderate demand for the enterprise network, or the external connections, on the grounds that free goods tend to be used inefficiently. Note that for this goal to be achieved, the pain (price) must be reflected directly to the individual making the usage choice... the more the pricing is aggregated (e.g. department-wide recharges) the harder it is to provide an effective feedback loop.
A fourth goal might be to provide budget predictability, which might tend to favor flat-rate quota-based schemes rather than usage-based billing.
Finally, it might be a goal to have a central network pricing policy that did not encourage individuals or departments to go into the networking business on their own, or to undermine a common network infrastructure, under the belief that they could do it less expensively than the central organization. (This is not to say that central organizations are always the most efficient, but there is evidence that local/departmental deployment decisions don't always consider the full breadth of lifetime infrastructure costs.)
Who/what do you police (or invoice)?
The answer may depend on local culture and existing infrastructure more than any theoretical or technical considerations. Institutions that are heavily into recharge accounting may be more inclined to build a network based on traffic or per-user costing than an organization accustomed to core funding infrastructure. Of course, hybrid solutions are also possible, indeed, likely --as when the basic infrastructure and best-effort service is centrally/core funded, but premium service is recharged.
There are (at least) two parts to the problem of collecting money for a network service:
Enforcement and Monitoring
Ultimately the network devices must enforce eligibility control and/or monitor usage based on bits on the wire. In the case of User ID, unless the identity of the user is inferred indirectly from one of the other (address/ID) parameters, there needs to be some authentication protocol between the end-system and one of the network devices. This might happen at the beginning of a "session", just like for dialup authentication, or --if the accounting is only needed for certain applications-- it could happen at application startup time. Either way, the result is that the network device ends up with some state such that the stream of packets coming from the end-system is either allowed to traverse the network at all, or is premium eligible. In the premium-eligible case, this may involve marking the packets as they enter the network, or not "unmarking" the packets as generated by the end-system. In addition, a mapping must be established between that user ID and either address or port ID if the network device must police or count packet flows.
There are some difficulties in using an addresses (MAC or IP) as the sole basis for a subscription that conveys the privilege of unrestricted access to preferred service. One is the fact that such a policy encourages "gaming" the system, e.g. a department might buy a single subscription, but for a machine acting as a gateway with many other machines behind it. Another is that addresses can be forged. However, schemes that use MAC address registration as part of network authentication or DHCP address assignment system might reasonably be extended to incorporate some notion of premium service subscription level.
In contrast to address-based subscriptions, a recharge policy based on usage or something like average number of users per department is less susceptible to gaming. However, the broad-based "flat tax" approach will trigger complaints from units that don't use the network very much (and silent glee from those who use it heavily), whereas usage fees are favored by those who don't use the resource very much. A flat-rate subscription model may also be combined with a quota mechanism, e.g. Committed Access Rate, and this also reduces the risk of "gaming" since (premium) access is not unrestricted.
Note, however, one caveat concerning quotas, such as committed access rates: the capacity of intra-campus links is likely to be far greater than that of off-campus links; therefore, if CAR quotas are used to police premium usage on-campus, a different (lower) CAR quota will probably be needed for off-campus traffic. Thus, it may be necessary to have distinct on-campus and wide-area subscription rates. Complexity-wise, that's a bummer.
Quotas or Usage?
The choice between a quota/allocation control method and a usage pricing feedback method may also depend largely on local culture. But not entirely... For example, one pricing issue that arises from the availability of multiple service levels in a QoS-enabled IP network is the observation that when premium service costs more than best-effort, and is based on usage, people will often try best-effort service first... and only if that is inadequate will they spring for the more expensive premium service. (Of course this is only true if the premium cost is "visible" to user.)
This means people will only use premium service when the network is congested, but that premium service is more costly than best-effort service (because it requires additional provisioning that might be rarely used). This observation has led many to conclude that any viable Internet pricing model will need to have a subscription component, wherein the user is paying some amount for the ability to ask for premium service, whether they do ask or not, rather than pure premium-usage pricing.
If a user doesn't feel the direct pain of the usage cost (i.e. there is no behavior shaping feedback) and if the time constant for adding capacity is too slow to keep up with demand growth, then even when aggregate recharges provide capital for increasing capacity, there may be scarcity that leads to a need for bandwidth allocation.
Scarcity can change behavior in anti-social ways, so another source of support cost is fraud or "gaming" the system (which is a frequent consequence of trying to manage scarcity). Sometimes the motivation is to make sure "I get mine", which leads to "hogging syndrome", e.g. staying connected to a shared modem pool even when not actively using it for fear of getting a busy signal the next time. In other situations, when there are charges associated with the resource, people may change behavior in order to avoid costs. For example, if premium service subscriptions in a network were associated with a physical port, or a single MAC or IP address, some might be incented to attach a "gateway" machine to that premium port, and "hide" many additional machines behind it (if machine count, rather than packet count, was the basis of the cost model).
In QoS schemes where the application's need (e.g. delay-sensitivity) is part of the prioritization decision, and that need is reflected in the TOS bits of the generated packet, the network has no way to validate whether or not the TOS bits have been set appropriately. In effect, they must be taken on faith, backed by quota and/or pricing mechanisms to "encourage" fair use. This is less of an issue when prioritization can be based on globally-agreed-upon TCP/UDP port numbers, but as previously discussed, IPSEC and port-agile apps may make that approach problematic.
In general, gaming/fraud/abuse are most likely when:
as, for example, when a flat-rate port subscription fee, or membership in a privileged group, entitles one to unrestricted access (to the network or to premium treatment).
In designing systems that manage scarce resources, there is always a balance between trying to prevent undesired behavior and trying to detect it after the fact.
The strategies chosen for intra-enterprise systems may well differ from those chosen for inter-enterprise solutions. For example, it may be most cost-effective to concentrate on post-audit approaches within the enterprise, whereas most of us would be more comfortable with an ounce of prevention when it comes to trusting folks in other organizations where there is no direct authority or accountability chain.
In a campus environment where direct cost recovery of either baseline or advanced network services is required, it is worth thinking about the cost-recovery choices available in terms of "gamability" and ease of administration. For baseline services, it may be reasonable to average over a large population and/or levy fees based on phone lines, rather than attempting to do detailed per-user accounting, especially if the entity to which the charge is associated is easily gamed. On the other hand, advanced services for which an enterprise may be paying a premium to external providers (e.g. Premium service from a national Internet service provider) may need to have their costs reflected back only to those who use the advanced services.
In network planning, ongoing support costs are just as important as any initial or one time costs. Therefore, ongoing costs are an essential part of evaluating QoS mechanisms.
Claim:
Note that increasing the probability that an application, if allowed to proceed, will get the resources it needs is not the same as increasing the probability of overall user satisfaction, since very few users are happy with busy signals (i.e. there is still no substitute for adequate capacity) and even if there are no busy signals, there must be safeguards to ensure that best-effort traffic still gets a "reasonable" amount of bandwidth, lest the "unprivileged masses" revolt.
Here are some of the factors that might contribute to the cost of a "hard" QoS mechanism:
And some generic cost drivers include:
What this boils down to is yet again the assertion that network administrators should seek the simplest possible solution consistent with their needs. More controversially, we might argue that "needs" are quite malleable in this space, and it might pay to set expectations low, then try to exceed them (rather than the other way around!)
It is feasible, though not necessarily trivial, to control and/or charge for traffic originating within one's own network. It is far more daunting to contemplate controlling or billing for traffic originating outside but destined for your own net. This is a particularly important issue for sites that are "net consumers" of traffic, since some NSPs charge on the basis of the maxium of inbound and outbound traffic. From a purely technical perspective, there are not that many different ways an enterprise switch or router might handle inbound packets:
If a packet arrives at an enterprise having qualified for premium treatment in earlier phases of its trip from source to destination, it seems a shame to simply ignore the predecence marking when it nears the destination --on the other hand, if the campus net is well-provisioned, it might not make any difference. However, even in such well-provisioned networks, we still seek to give preference to packets that need or deserve preferential treatment, as in the case of delay-sensitive applications.
While one might configure the enterprise border routers to only preserve the premium marking if the application type (TCP/UDP port number) is indicative of need, this is probably a losing battle for the reasons cited earlier. Thus, the most realistic strategy may simply be to respect the premium marking on the incoming packet, on the grounds that the sender deemed the flow worthy of preferential treatment, and we lack any better way to distinguish worthy from unworthy packets.
The more interesting questions may be a) should the recipient of high-priority packets "pay" for them in some way (e.g. via pricing or counting against some quota)? and b) are there cases where incoming best-effort packets should be marked at the enterprise border to become premium packets? (For example, if destined for a "privileged" user or application, or if they were associated with a generic delay-sensitive application.)
Unfortunately, there is no easy way to determine if incoming traffic is desired or spurious. Any charging or metering mechanism for incoming traffic is vulnerable to inequity in the face of Denial-of-Service attacks, for example. (Indeed, some DoS attacks can also cause unintended packets to flow in response). This situation is far from ideal, since there are important and popular applications (e.g. WWW browsers) which trigger large amounts of incoming data, and relatively little outgoing data.
Even if on-campus needs can be met via conservative (ample) provisioning and simple class-based-queuing strategies, we must consider the interface between the campus network and wide-area links where congestion is most likely.
In this context, moderating demand means reducing what users (premium eligible users --which might be everyone) ask for, in contrast to letting them ask, and then having them be told "no" via busy signal (admission control). That is, we are talking about a post-audit feedback, or marketplace pricing, mechanism, rather than a quota-based prior-restraint strategy. The goal here is to explore the viability of using a feedback mechanism rather than a quota mechanism in order to avoid busy-signal syndrome, on the grounds that a network administrator's life is happier when dealing with pricing complaints than busy-signal complaints. Secondarily, a price-based feedback model holds more promise for expanding the resource as need grows, and may even be accepted as preferable to quotas in terms of fairness.
In deciding among various prior-restraint or post-audit/feedback mechanisms, we need to understand what the NSPs are actually going to do. Some of the possibilities that may exist for buying bandwidth include:
Charges are likely to based on the maximum of either incoming or outgoing traffic, or worse yet, the sum of incoming and outgoing --unlike settlements for peering agreements among providers wherein incoming and outgoing traffic offset each other for purposes of settlement charges.
Envision a feedback control system with the following elements:
user -> app -> campus net -> border router -> possibly congested link -
\---------------<<-----economic or social cost--------<<-------------/
The premise here is that adding capacity on such a link is a long-term and/or costly proposition, so the operational requirement is to keep demand commensurate with currently-available capacity either by admission control (prior-restraint) or by affecting the behavior of users and perhaps applications.
The user moderates his/her demand for premium bandwidth based on perceived cost/benefit. If benefit is seen as positive, and cost (either economic cost or social cost) is perceived as zero, demand will be infinite. i.e. Tragedy of the Commons time. This situation would necessitate allocation strategies and a prior-restraint control model, whereas a post-audit recharge feedback method should work if there is perceived cost (monetary or otherwise) to the user.
The application moderates demand for premium bandwidth based on what the user asks it to do, and what the application developer thought it might need. If it has a way of determining the current state of the network, then it may be able to adapt its needs to current conditions.
Our goal for the campus net design is to be performance-transparent, as if the end-system was directly connected to the border router and wide-area link. Thus, it is ideally neutral in terms of the feedback loop, but to the extent campus network links or routers constrain traffic, they represent a possible source of moderation for wide-area bandwidth.
The contribution of the border router in this equation is hypothetical, but it might offer some way to communicate to the application the current state of congestion.
The purpose of this section is to summarize the key assumptions, key questions and key choices confronting network administrators who are about to be dragged into the deep waters of QoS.
The campus network world we seek to design has the property that extremely few packets will be dropped on the floor, and extremely few premium packets will be delayed. This means that instantaneous best-effort traffic peaks must not result in queue lengths that trigger packet loss beyond the baseline level needed for TCP to adapt, and premium traffic peaks must not result in queue lengths that imply excessive delay.
Recall that the QoS toolbox we have available includes the following techniques:
Our challenge is to figure out which of these general approaches to use for our campus/enterprise network design, and how to deploy them.
The matrix below lists some key design decisions and the possible alternatives for each one:
Entity being managed? PhysPort, MAC, IP, userID, flowID
Eligibility control? none, subscription, privilege, destination
Admission control? none, availability, quota, schedule, bid
Access quota (CAR)? none, fixed, subscription-based
Consequence of going over? extra charge, drop, downgrade
Behavior shaping? none, price, inconvenience, social pressure
Edge device actions: none, marking, admission, shaping, policing
Core router actions: none, marking, admission, shaping, policing
Border router actions: none, marking, admission, shaping, policing
L2 Switch prioritizes by: flow-setup, 802.1p/Q, TOS, TCP/UDP port
L3 Router prioritizes by: flow-setup, 802.1p/Q, TOS, TCP/UDP port
Best-effort traffic protection? yes, no
Best-effort access bill? none, dept {tax, subs, usage}, user/proj usage
Premium access bill? none, dept {tax, subs, usage}, user/proj usage
NSP premium cost recovery? none, dept {tax, subs, usage}, user/proj usage
Basis of LAN premium recharge? CAR, CAR+overage, in-out, max(in,out)
Basis of WAN premium recharge? CAR, CAR+overage, in-out, max(in,out)
Different quotas for LAN, WAN? yes, no
Incoming premium traffic? respect, downgrade, charge, police
Special events provisioning? add capacity, schedule, pre-empt, reconfig
The purpose of this section is to outline a specific approach to enterprise QoS that meets the following overall objectives:
This strawman proposal is obviously designed with the University of Washington in mind, but I would expect our situation to be similar to many others. The UW campus network architecture is consistent with the reference model described previously, with a four-level hierarchy of network devices:
We currently offer three levels of service:
The ultimate goal is for everyone to be attached to a 10/100 FD port, backed by Gigabit Ethernet infrastructure, but since most UW buildings still have category 3 cabling, this goal is some years off. (In addition, some servers would presumably be connected directly at gigabit rates.)
In principle, switched 10Mbps ports could be configured for FullDuplex operation and thereby become viable for use with QoS-sensitive interactive applications; however, it appears that this scenario would require manual configuration of both the end-system NIC and the specific edge switch port, and careful attention to eliminate any intervening Half-Duplex hubs. Conclusion: supporting 10Mbps Full Duplex operation appears to be an administrative nightmare, and therefore cost-prohibitive unless there is a monthly fee associated with the service, perhaps viable if combined with premium service (high-priority queue eligibility.)
Many end-systems will be running "legacy" operating systems and apps (such as Windows 95 :) that have no QoS capabilities (e.g. traffic marking, shaping, built-in RSVP.) This means that unless the campus QoS mechanism is based on physical port premium subscription/eligibility or legacy packet header port numbers, there won't be much demand for high-priority switch queues for awhile!
Similarly, because most buildings still have cat-3 cableplants, it will be awhile before a premium 100Mbps service would have many takers. Yet, there is a clear goal to expand the switched 10/100 cat-5 infrastructure, so --like the transition to newer QoS-aware apps and operating systems-- this is a question of migration timing.
Of all the possible requirements one might have for QoS, many of which were discussed in chapter 04, we list here the subset that drove the strawman design.
Service levels
The system must support packet prioritization based on some combination of user desire, privilege, or application need. Ideally it could do this even with today's operating systems, but realistically the full promise of eQoS will await the next-generation of end systems, which will allow applications to request expedited forwarding or other DiffServ per-hop- behaviors. Therefore, we will concentrate on using of TOS/DiffServ bits to indicate need/desire, and optionally consider privilege via physical port subscription.
It is not yet clear whether or not it will make sense to offer a 100Mbps premium port subscription option (much less a 10Mbps premium port option), as opposed to relying on a laissez faire (anyone can ask for preferred service) approach to premium requests, or a post-audit behavior modification strategy, but it is a goal of the architecture to be able to a accommodate such offerings if circumstances warrant.
Simplicity/reliability
It is a goal to be able to map whichever priority-indicating bits are used in the plan into switch and router queues with minimum system and management complexity.
Moreover, queuing and forwarding decisions within switches and routers should not require any information that is not either in the incoming packet or in the current device configuration. For example, a packet queuing or forwarding decision should not require real-time access to an authentication server or an external policy database.
Policy management
It should be possible to define a site-wide prioritization policy that can be implemented via quasi-static configuration mechanisms. Physical port subscription policy would meet this requirement, whereas per-user or per-group forwarding policies would not.
To reiterate, our simplicity/reliability objective requires a policy management model such that interior switches/routers make their queueing (and forwarding) decisions based on bits in packets combined with simple static and global configuration state, rather than requiring lookup of cached or external dynamic policy state or identity mapping.
Border processing
At the campus border, we need to be able to accommodate:
In border routers, it will also be important to support nested allocation policies, such as allocating "20% for VoIP" while also supporting DiffServ processing within the aggregate percentage allocations. MPLS virtual circuits will probably be very important for traffic engineering and segregation.
Switch requirements
Contemporary 100Mbps Ethernet switches can vary in price by over an order-of-magnitude. The good news is that even some of the lower-priced switches appear to offer sufficient capabilities for this strawman, namely: support for prioritization into at least two queues, based on TOS/DiffServ bits, and (in edge switches) the ability to associate a physical port with a particular VLAN to support the premium subscription idea.
If/when it becomes available at low cost, the ability to do proxy traffic shaping on behalf of the end-system would appear to be a welcome addition to the repertoire of edge switches.
The following sections describe our three-phase "minimalist" eQoS approach.
Overview
We start with as much bandwidth in the enterprise backbone as can be reasonably provisioned using contemporary Ethernet switches and routers, in order to have plenty of headroom for instantaneous peaks of both best-effort and premium traffic.
Second, to the extent possible, we seek to distribute policy decisions semi-statically into device configurations (e.g. marking a port as "premium" eligible) in order to minimize need for dynamic policy database lookups. However, it would certainly make sense to tie the static/offline switch configuration process into a centralized subscription database or a metadirectory driving the network configuration process.
Next we plan for three implementation phases, secretly hoping that the second and third phases won't be needed:
Phase 1: Unrestricted access to premium bandwidth
Phase 2: Addition of post-audit feedback to moderate demand
Phase 3: Premium-port subscriptions to add eligibility control
In order to keep the system as simple as possible, the "going in" (Phase 1) postulate for this strawman is an "honor system" approach, backed up by a Phase 2 of post auditing and the possibility of adding Phase 3, a "premium port" option at extra cost if needed. However, in all phases, end-system applications/users would indicate their need/desire for expedited service by causing the TOS bits in outgoing packets to be marked accordingly.
Phase 1 assumes that a laissez-faire or honor-system approach to packet prioritization is completely sufficient to moderate demand for premium bandwidth. That is, any end-system or application is allowed to request (via TOS/DiffServ bits) preferential forwarding for its packets without restriction. The motivation for this policy is to minimize complexity within individual subnets in particular, and also to avoid putting any barriers in the way of fully utilizing local subnet bandwidth, which may well be greater than in any other part of the network. The justification for why a laissez faire approach may be viable is based on the arguments listed in section 6.5, namely: the belief that the capacity of new switches and GE backbones, combined with statistical usage patterns of apps that request priority, will be sufficient to assure reasonable performance without explicit demand controls in the edge or interior switches within a subnet.
Phase 2 follows if it turns out that the unrestricted or laissez faire approach is being abused and a significant number of users are gratuitously marking most or all of their traffic as high-priority. The method for moderating such "excessive" demand for high-priority bandwidth would be based on post-audit feedback and behavior modification strategies. Sampling techniques may be applicable. The specific implementation chosen will depend on the monitoring tools available in the selected switches. For example, there may be a way to generate SNMP alerts if high-priority queue lengths exceed a certain threshold, or a way to measure the ratio of best-effort vs. premium ratios for different end-systems. Based on this information, users could be notified of the anomoly, with optional public humiliation of those well above the norm :)
Phase 3 involves introducing a subscription service wherein the priority of packets sent into the network from a subscribed physical Ethernet port have their priority bumped up a bit over packets from normal (unsubscribed) ports when they get to the first campus backbone router. This is accomplished by configuring one or more "premium" VLANs to which the physical port would be mapped. The first-hop backbone router uses the VLAN tag to indicate which queue and committed access rate to use. (Ethernet 802.1p frame priority bits could also be used to convey the port subscription level to the router, but "p" bits require VLAN tagging to be enabled anyway, so they are superfluous for our purposes.)
It is tempting to arrange for prioritization based on IP port number (i.e. application type, from which we might infer its "need"), since this could presumably be done "now" and work with any existing end-system. However, the limitations of this approach (documented in earlier sections) lead us to conclude that it isn't worth it. Plus, not all multi-queue switches support this option.
Prioritization policy
Seven traffic classes are defined with mappings for both two-queue and eight-queue devices, here assumed to be switches and routers respectively:
Traffic Class Switch Priority Router Priority
- - - - - - - - - - - - - - - - - - - - - - - - - - -
Network Control high 7
Reserved - 6
Dedicated VoIP high 5
Premium Expedited high 4
IGMP multicast high 3
Baseline Expedited high 2
Premium Default normal 1
Baseline Default normal 0
Nomenclature:
"Premium" refers to packets coming from a "premium" port
"Baseline" refers to packets coming from a "non-premium" port
"Default" refers to default or normal priority
"Expedited" refers to any DiffServ value other than default
Note that either "baseline" physical ports, or (if implemented) "premium" ports can emit both normal (default priority) packets and those marked to request preferred (expedited priority) treatment, but in either case the corresponding "premium" packets would take precedence over the baseline packets. In eight-queue devices (e.g. the core backbone routers) this would appear to address the concern about a VIP's email taking precedence over other folks' real-time delay-sensitive conferencing traffic.
DiffServ code points (the values of the TOS bits) must be mapped to specific priorities in the switch configurations. Here only two priority values would be used: normal and high.
In Phase 1, edge and interior switches enqueue incoming packets in accordance with the TOS bits and the priority schedule above. Outgoing packets are not modified. Routers do the same. If 802.1p bits are set by the end-system, they are ignored. Application port number is also ignored.
While experience may show that premium-port subscriptions are not needed to moderate demand for preferred service, it would be reassuring to know that the idea can be implemented if needed. Hence, our Phase 3 plan...
The plan allows for subscriptions for (possibly multiple levels of) premium service that are associated with physical ports. The decision to use physical ports rather than user ID or device addresses is based on the desire to avoid schemes that are amenable to gaming by users (e.g. charge-by-address) and schemes that require the complexity/reliability risk of per-flow dynamic/realtime authentication. The physical port subscription idea is primarily oriented to non-roaming desktop systems or servers. In addition to anticipating multiple service levels at one's primary location and system, we also need to consider premium access from alternate locations or platforms. (This goal is somewhat at odds with the idea of relying on static policy configurations, but only involves dynamic port reconfiguration at "network login" time, and not any per-packet or per-flow authentication decisions.) Subscription access (as opposed to laissez faire access) to premium bandwidth from roaming locations would require user or device authentication.
It is a feature of this port subscription plan that it does not prohibit users from attaching more than one computer to a physical port (e.g. via a desktop hublet). The premium subscription rate is based on aggregate traffic committed access rate. This avoids both inconvenience and temptation to game the system by users, in contrast to schemes based on the number of subscribed IP or MAC addresses.
To implement premium (physical) port subscriptions, we implement one or more VLAN definitions corresponding to the premium access subscription level, with each level having an implied committed access rate. The edge switch configuration associates the physical port with the appropriate VLAN, and also associates a specific 802.1p priority with each VLAN. The normal traffic plus that on all of the premium VLANs would be part of the same IP subnet; the VLAN tags and/or 802.1p priority bits would simply be used by the router as one input to its queuing decision. VLAN tagging is necessary to carry 802.1p bits, but those priority bits might be superfluous depending on the capabilities of the router (i.e. the VLAN tags might be sufficient to map the incoming packets to the appropriate router queue.)
Packets entering a core router and desiring premium treatment would be subject to a Committed Access Rate corresponding to the 802.1p priority bits and/or the incoming VLAN tag, which should reflect the original physical port subscription level. For packets with TOS/DiffServ bits indicating a desire for premium treatment and VLAN or 802.1p bits indicating they came from a premium-eligible port, the router would queue them according to the prioritization policy presented above and apply per-flow policing based on the CAR globally associated with the indicated subscription level.
An alternative strategy for implementing preferred-service subscriptions might involve MAC address registration of end-systems, with the edge switch port being dynamically reconfigured at DHCP lease acquisition or renewal time. However, we are not aware of any edge switches that support reconfiguration based on signalling from a DHCP server.
Core router processing
In the laissez faire scenarios (with or without post-audit humiliation!) priority queuing in the core routers would be based solely on the TOS/DiffServ bits set by the end-system. In the premium-port subscription scenario (Phase 3), access to highest-priority queues in core routers would be limited to packets originating on subscribed physical ports (which may require authentication to use if not at one's primary location). Multiple levels of "premium-ness" can be accommodated, at presumably different subscription rates. The port subscription level would be denoted on packets via the 802.1Q VLAN tag.
Combinations of subscription-based priority and laissez faire priority requests are also possible, with traffic from an application requesting preferential service on a normal port taking precedence over regular traffic from a premium port (but of course that priority would be lower than preferential service requests on a premium port).
Packets from a premium port that exceed the corresponding committed access rate for that port will be downgraded to a lower priority.
Traffic marking and policing to enforce Tspecs or quotas (or proxy shaping for end-systems that cannot) is best done by the edge device, where packets enter the network from the end-system. However, in the interest of minimizing edge switch configuration complexity (and possibly cost) we defer the policing function to the core router, which is also likely to be the first place where congestion is encountered in a modern switched network.
Core routers might be configured to do aggregate per-queue shaping on output ports to counteract the fundamental burstiness of Ethernet traffic.
Border router processing
It is probably going to be necessary to control demand for wide-area premium bandwidth via usage recharges that reflect scalable provider pricing. Details deferred until such a premium (commodity Internet) offering materializes. However, if implemented, the same accounting machinery could be applied to premium on-campus traffic if needed (but we're optimistic that the local-traffic recharge scenario can be avoided.)
It is a design goal to make the enterprise backbone transparent to call-setup signalling protocols (e.g. RSVP) in case they become important for either end-system to end-system or end-system to border-router signalling. Until such time as suitable WAN bandwidth-brokers exist, allow for manual border router reconfiguration to accommodate special projects.
If signalling and reservations are not used for wide-area premium access, then the same criteria used for on-campus queuing decisions can be mapped to the appropriate method for signalling wide-area bandwidth requests, e.g. TOS bits.
Border routers will surely be configured to shape traffic headed for potentially congested wide-area links. This shaping will probably be per-queue, based on the characteristics of the output link, rather than based on the characteristics of individual flows. Even if traffic reaching the border router has already been shaped at the edge or core to avoid the adverse peaking of unshaped fractal traffic patterns, re-shaping at the border based on output link characteristics seems much more scalable than any attempt at per-flow shaping.
It's not clear how incoming premium traffic should be handled. Respecting the premium status of those packets seems reasonable; the only question is whether the recipient should have to pay for them or have them quota limited. The answer will depend on how the actual NSP contracts evolve, but some form of recharging for incoming premium traffic may be very difficult to avoid if it represents a significant (or dominant) part of the bill from the NSPs.
End system considerations
When this document was first formulated, operating systems with QoS support seemed very far in the distance --even farther than upgrades to category 3 wireplants! Accordingly, the original idea for a campus strawman was to emphasize the use of application type (as indicated by TCP/UDP port numbers) for prioritization decisions, plus allow for the use of premium subscription ports. Both of these mechanisms had the virtue that they would work with any old end-system and most existing applications (modulo the limitations of using port numbers).
Since then, we have changed positions to de-emphasize use of IP port numbers and increase the emphasis on use of TOS/DS bits, which will typically be set by the end-system application or operating system. Why? Because:
As a result, the current strawman relies on pure over-provisioning to accommodate "legacy" end-systems, unless/until they are plugged into a "premium" Ethernet port.
In addition to the ability to set TOS/DS bits, end systems should also be able to do their own traffic shaping. And applications should, to the extent possible, be rate and latency adaptive. (I think JPL should conduct network programming "bootcamps" to explain to folks how to live with high-latency network links!)
Some end-systems may have special requirements. Therefore, we should allow for special-case access to sequestered campus or WAN bandwidth either via separate physical infrastructure, or MAC or IP address of the device in question, or edge-switch packet marking (based on switch configuration driven by subscription/policy database). A VoIP gateway would be an example of a special-purpose device where premium bandwidth/queues might be allocated on the basis of the IP address of the gateway.
Bandwidth brokers and signalling
The intent is to make the campus network itself neutral with respect to signalling and scheduling paradigms. While not considered particularly useful within the campus backbone, the jury is still out with respect to wide-area access and the campus net should not get in the way of experiments to understand more about the usefulness of these approaches. Accordingly, to the extent that end-system signalling to another end-system or to the first congestion point is desired (via e.g. RSVP), we seek to have the campus backbone RSVP-transparent (i.e. both unaware of RSVP and close to congestion-free for delay-sensitive and/or premium traffic. An end-system should be able to signal a border router acting as a bandwidth broker as if it was directly connected to it. Moreover, we would welcome the ability for end-systems to get real-time information about the current state of congestion in the network in order to facilitate application adaptation.
Summary of prioritization processing
Edge and interior switches enqueue incoming packets in accordance with the TOS/DiffServ bits and the priority schedule above. Edge and interior switches ignore 802.1p priority bits. Edge switches optionally set 802.1Q VLAN tags corresponding to premium subscription level. IP (TCP/UDP) port number is ignored by all devices. Routers enqueue based on both TOS/DiffServ bits and VLAN tags (if any).
The following list outlines the role of different network devices as a packet leaves an end-system and traverses the campus network.
Although the technical and policy decisions described above are not without drawbacks and uncertainties (perhaps most notably the honor system assumption of phase 1), there are always lots of roads not taken. Below are a few, with the reason they were rejected.
This is obviously not the complete set of roads not taken! It is simply a representative sampling.
The principal conclusions of this paper are:
Many research questions remain, such as:
(What if we could just assign different colors to different apps?)
Finally, consider this document to be a first cut, a work in progress. We have explored a wide variety of problems relating to QoS, and postulated some tentative solutions and conclusions... but they still need to be tested intellectually and practically. Continuing feedback is welcome.
The author would like to thank the following folks for their comments on prior drafts of this document and/or related presentations:
Steve Corbato
Van Jacobson
Ken Klingenstein
Chuck Song
Lori Stevens
Ben Teitelbaum
John Wroclawski
-30-
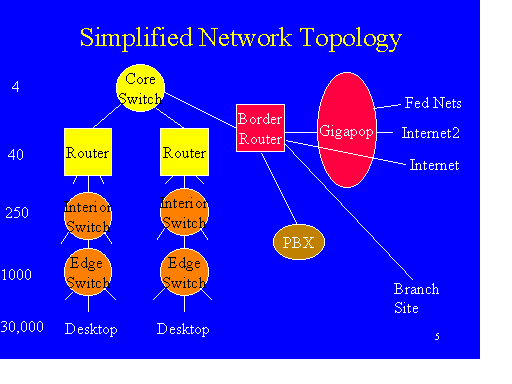{kind=link}
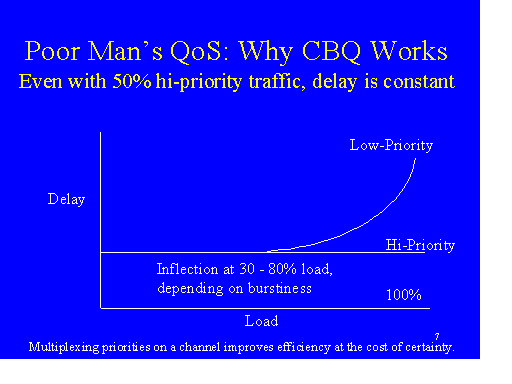{kind=link}