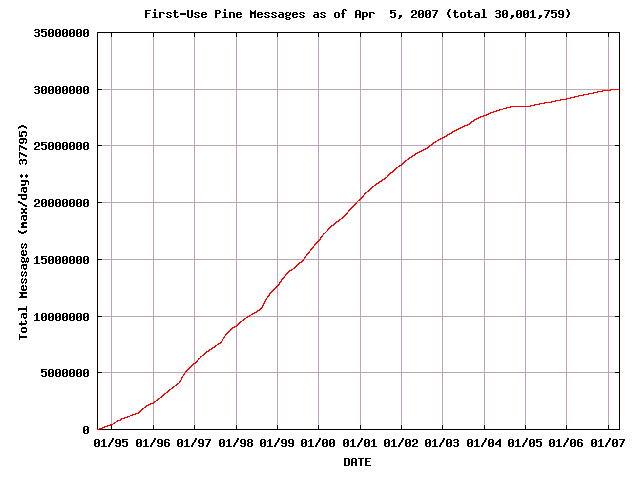
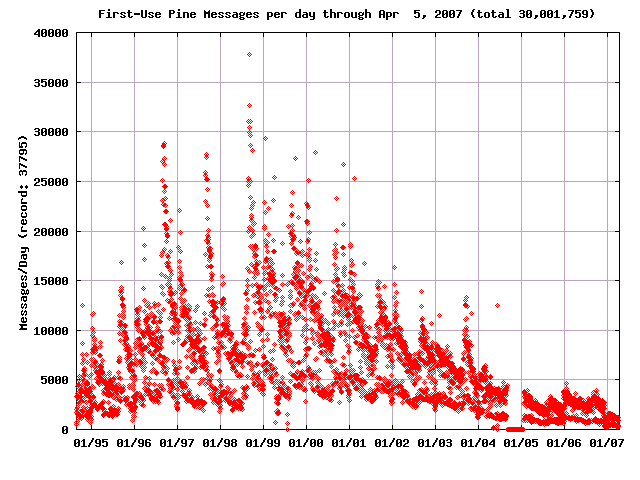
Pine First-Use Statistics
Beginning with Pine version
3.90 (August 1994), Pine has offered new users a (usually one time)
opportunity to send us an email. Initially, the offer was to send for a
document called "The Secrets of Pine", which was a brief overview of using
Pine and some release-specific information. At some point the document
was renamed to "Getting the most out of Pine".
Our not very secret agenda behind these offers was to help secure continued
funding for Pine development by demonstrating widespread interest in Pine.
We measured this interest by counting the requests we received from new
Pine users.
For reasons we were never really able to discover (despite numerous attempts)
between .001% and .01% of people who received a Pine document
complained that they'd never heard of Pine, never asked for a document,
and occasionally threatened legal action for receiving "spam".
For this reason, beginning with the Pine 4.0 release, Pine no longer
offered anything more than an opportunity to be counted as an anonymous
Pine user (via a message we don't answer).
We have no way of knowing for sure what fraction of new Pine users
worldwide send us mail when prompted, but we did measure the fraction on
our campus timesharing systems and it was about 50%. We feel this may be
somewhat representative worldwide, especially if it indicates a complete
disregard for the question and a random yes/no selection!
There are some anomalies in our data:
-
Pine prompts "new users" based on the existence and contents of their
".pinerc" file. If it is unreadable or unwritable or gets deleted, users
may get re-prompted. Because it is computationally expensive to test for
uniqueness of Pine users, we have not routinely done so and only
occasionally sample the replication rate.
-
Due to a programming error in Pine 3.92 (released March 1996), all Pine
3.92 users (even those who had used an earlier version of Pine) were
re-prompted at first use. Checking the replication rate through April
1998, we found that for just Pine 3.92 and above it was 11% and overall it
was 16%.
-
A large number of Pine users are students at universities. As they graduate
and their account names get re-used by new students, some apparent
duplication is occurring which is not real duplication. We have not
attempted to quantify this.
-
Presumably because of some mailer misconfiguration, an occasional site sends
a surprising number of identical requests (37,644 in one episode) and
we've now accumulated over 200,000 from "root@localhost.localdomain".
-
In December 1999, we were surprised to discover the replication rate for
the year had jumped to 29% (double that in 1998). We now believe this is
mostly caused by programming errors in Pine 4.00, 4.10, and 4.20 similar
to that which caused the reprompting in Pine 3.92; although along the way
we also discovered that a remarkable number of users seem willing to
just press <enter> a few extra times when starting Pine to live
with unreadable or unwritable .pinerc files (and the reprompting at every
invocation this causes). The 1999 replicates include:
| >1000 | from each of a dozen very patient Pine users; |
| >100 | from about 900 users; |
| >10 | from about 9000 users; and |
| >1 | from about a quarter million users. |
We are considering changes to Pine to reduce this.
With all this in mind, we currently estimate the number of unique email
addresses we've seen to be roughly 33% fewer than the raw number of
messages we've received. (But except as stated otherwise, our graphs below
are based strictly upon the raw numbers we've received). Also remember
that some fraction of users decline to send us email when prompted and
some sites choose to disable the option entirely.
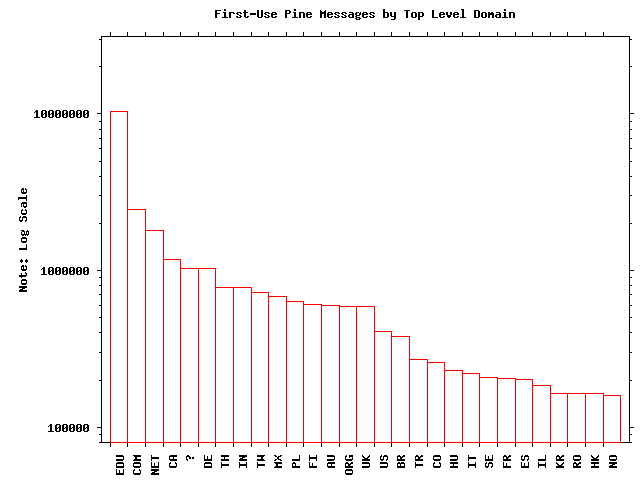
90% of the first-use email we received came from these domains:
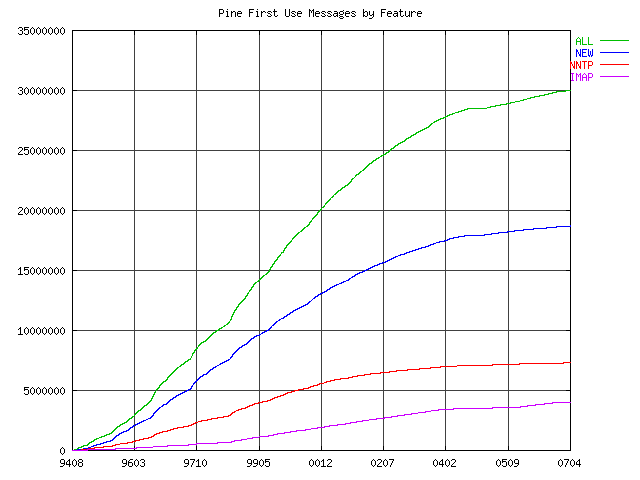
The body of each first-use email also tells us whether that instance
of Pine is configured for IMAP and/or NNTP use and whether the user was
NEW to Pine (had no .pinerc yet).
This graph shows how that has changed over the years:
Other things we've learned from receiving these emails:
-
You can do a remarkable amount of work on a small unix computer if you
want to. The autoresponders are shell and perl scripts and the first
20.7 million of these Pine emails were received and handled by a single
decstation model 25 running Ultrix. It was about a 25 MIP processor
with a physical memory limit of 40 megabytes (about a 486-class
machine). Mid-February 2001, the decstation developed problems and was
replaced with a (faster/better/cheaper) linux system running
the same scripts (with minimal changes).
-
When one site (or country) has very poor connectivity (99% ping packet
loss) they can still eventually get short requests through to us but we
are at a disadvantage when we have to send a large reply back.
Before we began consolidating requests by site so we could reply to
multiple new-user messages at a site with a single message to multiple
recipients, we would often find our address space entirely full of
sendmails trying to deliver Pine documents to a single poorly connected
site (or country). We originally modified our sendmail so that queue runs
would learn about unresponsive sites from each other and skip them for a
while. Now we simply rely on modern sendmail's host status directory and
MinQueueAge features.
-
When summer ends and a new class of students starts using Pine at schools
and universities worldwide, we'd better be prepared to handle the mail.
When we first started doing this, we had no idea what that demand would
be and every fall we still watch closely. (Note the bump each fall as a
new freshman class of students first uses Pine.)
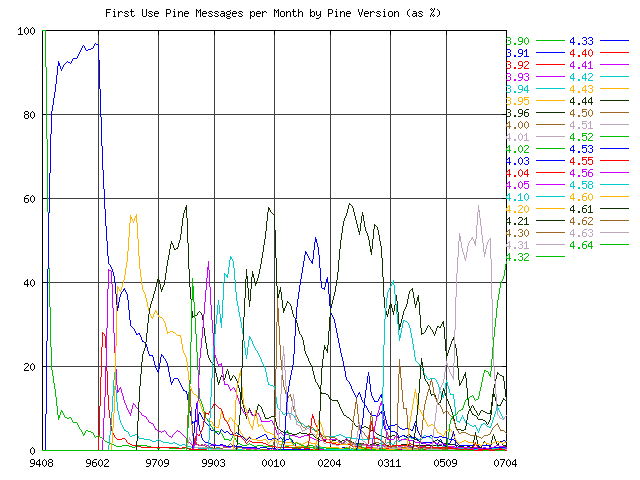
Here is a graph showing the evolution and acceptance of Pine versions.
See also the official
Pine Release Chronology.
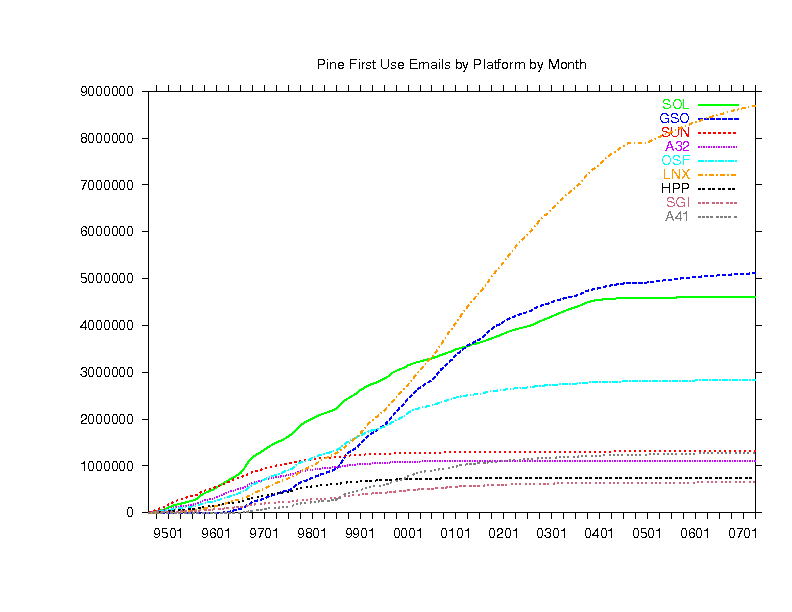
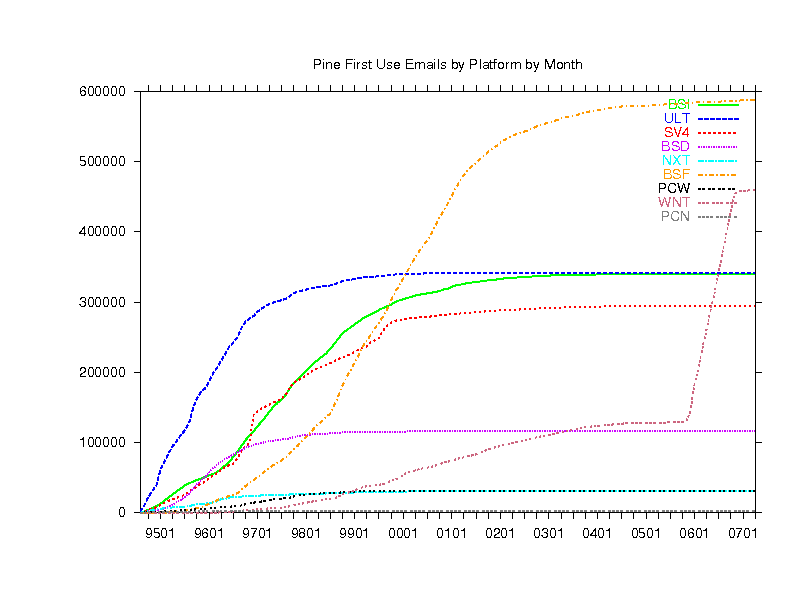
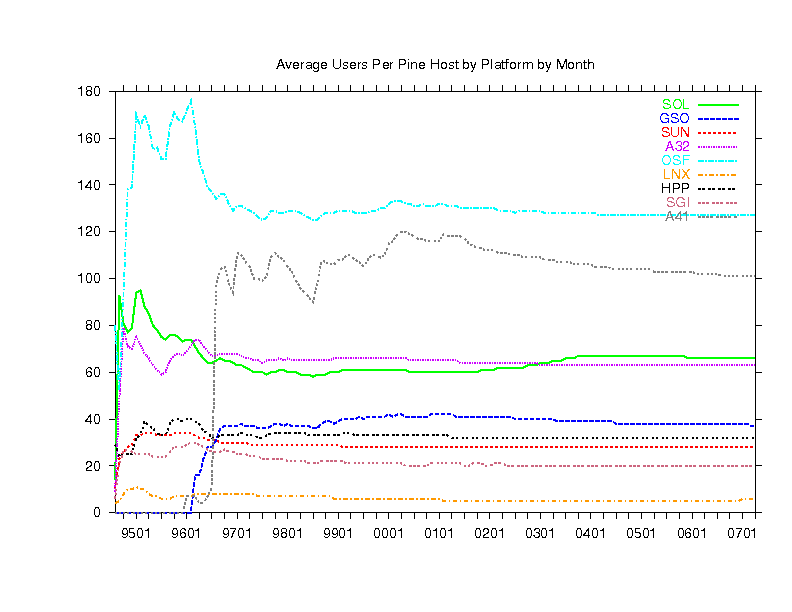
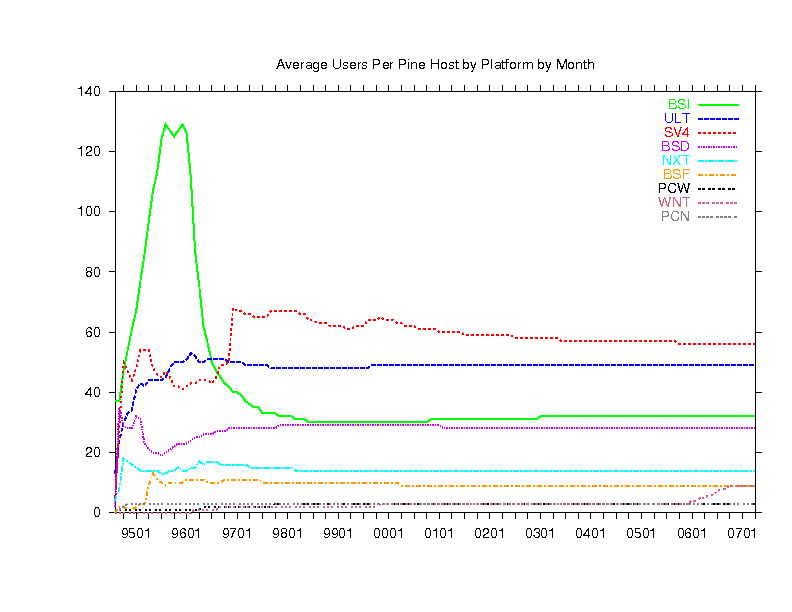
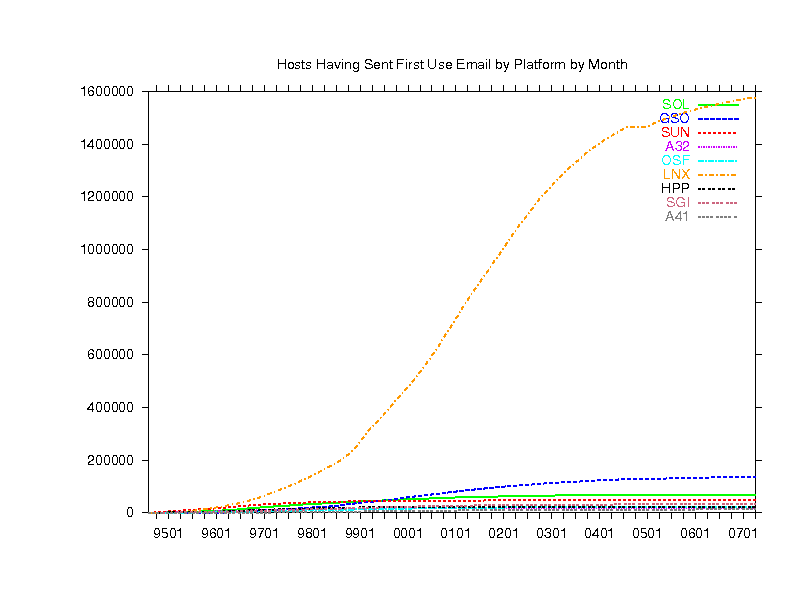
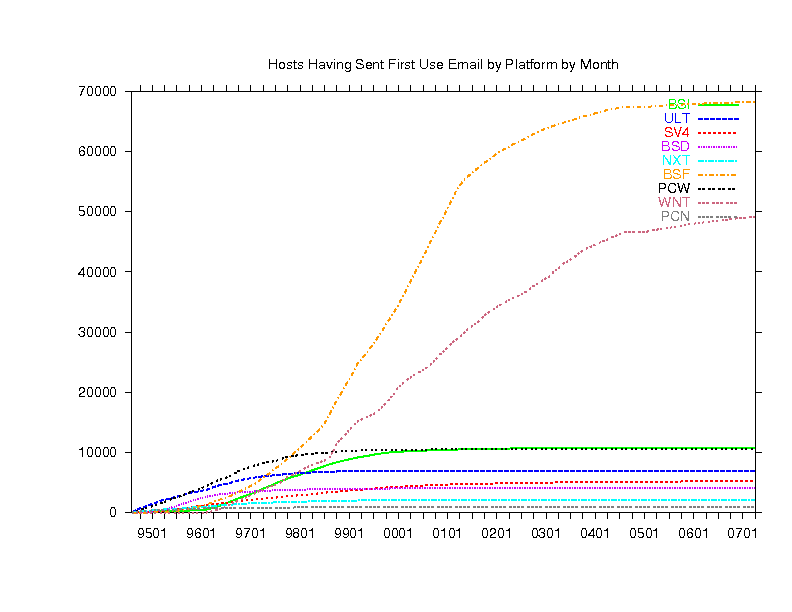
Finally, below are 6 graphs (in 2 columns of 3 graphs) showing Pine
use by host platform as deduced from the three letter code in the
Message-ID of the email we receive. In each of the 2 columns:
- The upper graph counts emails received from each platform.
- The lower graph counts distinct hosts of each platform.
- The middle graph is the top graph divided by the bottom graph.
- The left and right columns are similar except the
most popular platforms are in the left column and the less popular ones
are in the right column (note the left and right graph scales may be very
different).
| LEFT | RIGHT
|
|---|
| SOL | Solaris | BSI | BSDI
|
| GSO | gcc Solaris | ULT | Ultrix
|
| SUN | Sunos | SV4 | SVR4
|
| A32 | AIX 3.2 | BSD | BSD
|
| OSF | Digital Unix | NXT | NeXT
|
| LNX | Linux | BSF | Free BSD
|
| HPP | HP | PCW | Windows 16bit
|
| SGI | SGI | WNT | Windows 32bit
|
| A41 | AIX 4.1 | PCN | Novell
|
These graphs show that BY FAR, the most common platform is Linux (see
lower left graph) but because of the large number of users timesharing
Sun, Aix and Digital Unix boxes (see middle left graph), most of the users
are still on those (see top left graph). You can also see which platforms
are used most by schools because they have the telltale bump at the end
of summer each year.